
Python爬虫案例1:百度图片搜索结果爬取
作者:Barranzi_
个人github主页:[github](https://github.com/La0bALanG)
个人邮箱:awc19930818@outlook.com
新时代的铁饭碗:一辈子不管走到哪里都有饭吃(还能吃上热乎的)。——佚名
免责声明:
本系列笔记撰写初衷就是为了分享个人知识以及个人学习历程中的感悟及思考,所涉及到的内容`仅供学习与交流`,请勿用作`非法或商业用途`!由此引发的任何法律纠纷`后果自负`,与作者本人无关!
版权声明:
未经作者本人授权,禁止转载!请尊重原创!

注:本文所有代码、案例测试环境:1.Linux -- 系统版本:Ubuntu20.04 LTS 2.windows -- 系统版本:WIN10 64位家庭版
请求URL及页面数据分析
-
目标URL
https://image.baidu.com/ -
目标数据
所需每一张图片的下载链接。
-
URL分析
-
请求百度图片首页,随机输入若干个搜索内容,查看其URL规律:
https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111211&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=%E9%AB%98%E5%9C%86%E5%9C%86&oq=%E9%AB%98%E5%9C%86%E5%9C%86&rsp=-1 https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1602205802368_R&pv=&ic=0&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&ctd=1602205802368%5E00_1483X858&sid=&word=%E6%9E%97%E6%9B%B4%E6%96%B0 -
总结其URL规律如下:
url = 'https://image.baidu.com/search/index?tn=baiduimage&word={}'
-
-
页面及所需数据分析
F12控制台抓包如下:
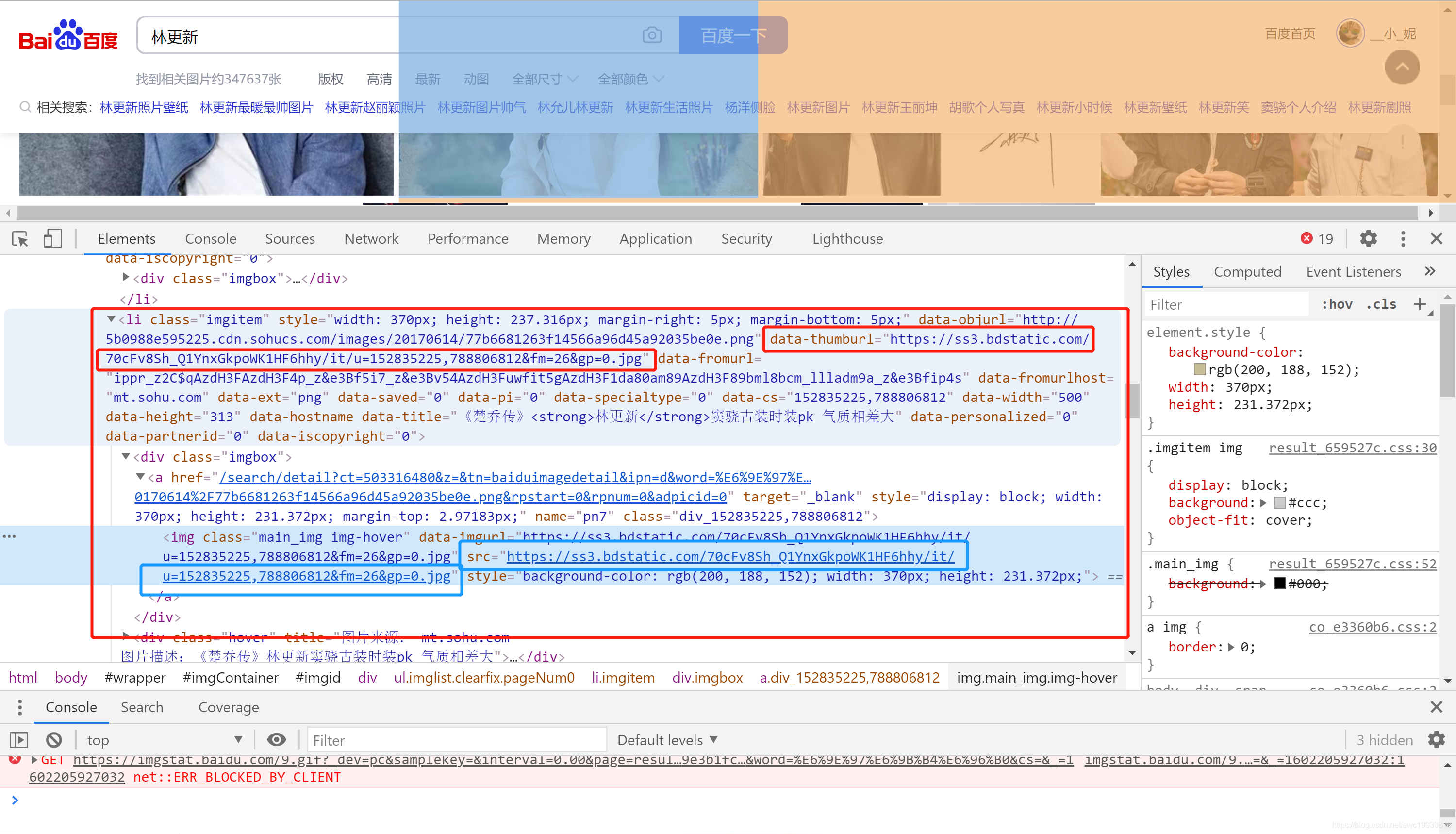
如图中所示,class为
imgitem的li的data-thumbURL属性及class为main_img img-hover的img标签的src属性中包含图片的目标路径;因为此处为HTML文档内部,所以我们可以采用xpath进行匹配:
//ul[@class="imglist clearfix pageNum0"]/li[@class="imgitem"]/@data-thumburl但,切换到response中发现,该部分内容并不存在于response中,所以该网页为动态加载网页,xpath匹配无效;
尝试在response的js代码中寻找目标URL:
"thumbURL":"https://ss0.bdstatic.com/70cFuHSh_Q1YnxGkpoWK1HF6hhy/it/u=962314285,2767891947&fm=26&gp=0.jpg"如上,所需数据在页面的response中js传递的参数内部。
确定采用re正则表达式进行匹配:
re.findall('"thumbURL":"(.*?)"',html)
编码思路
-
第一步:确定目标URL格式,伪造headers
url = 'https://image.baidu.com/search/index?tn=baiduimage&word={}' headers = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'} -
第二步:拼接URL参数构造最终请求URL
注意:因为word此处为查询参数,需要进行urlencode编码后再传入:
word = input('你想要谁的照片?请输入:') params = parse.quote(word) url = url.format(params) -
第三步:发请求获得响应,将响应内容转为文本格式,为下一步解析做准备
html = requests.get(url=url,headers=headers).text -
第四步:数据筛选,使用re正则表达式进行匹配
link_list = re.findall('"thumbURL":"(.*?)"',html) -
第五步:持久化存储。
创建图片存储目录,从解析得到的图片链接序列依次读取每一张图片的URL,并发送请求获得图片数据,保存为二进制格式,进行文件写入,生成图片内容
# 1.创建图片保存路径,保存图片到本地 directory = '/home/anwc/桌面/{}/'.format(word) #os.path.exists(directory)表示目录存在 #如果目录不存在(即先判断是否已存在目标目录) if not os.path.exists(directory): # 创建空目录并命名 os.makedirs(directory) # 2.循环的对目标图片发起请求获得响应 for link in link_list: # 请求图片获得响应 html = requests.get(url=link, headers=headers).content # 拼接我们想要的图片文件名(包含路径) filename = directory + '{}.jpg'.format(link[-24:-15]) # 写入文件 with open(filename, 'wb') as f: f.write(html) f.close() print(filename, '下载成功')
编码实现
-
基础编码
#导入所需模块 import requests from urllib import parse import re import os from lxml import etree #------第一步:确定目标url,伪造headers,为正式发起请求作准备------ # 1.确定基本url格式 # 即你要向哪个网站发起请求,本案例中,我们要在百度图片网站上搜索明星图片 # 即需要向百度图片网站发起请求 url = 'https://image.baidu.com/search/index?tn=baiduimage&word={}' # 2.明确目标url基本格式 # 目标关键词:你想搜谁的图片,就输入谁的名字,该关键词最后要拼接进基本url word = input('你想要谁的照片?请输入:') # 3.因为直接输入的字符类型为字符串,并不能直接使用,所以需要转unicode码 # 转unicode码 params = parse.quote(word) # 4.拼接得到最终请求url url = url.format(params) # 5.伪造headers:说白了就是骗浏览器“我们不是机器,我们是人~” headers = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'} #------第二步:发请求------ #向网站正式发起请求,获取页面数据,转为字符文本 html = requests.get(url=url,headers=headers).text #------第三步:数据筛选 # 响应结果中的html文本内容很多,需要从中找出我们所需的图片url文本并采用合适的方式保存以备后续使用 # 筛选、解析方式很多,介绍两种基本方式 # 1.使用xpath匹配 # dom = etree.HTML(html) # link_list = dom.xpath('//ul[@class="imglist clearfix pageNum0"]/li[@class="imgitem"]/@data-thumburl') # 从得到的响应结果中可以看到,目标图片的路径不在html元素的属性或内容中,而是在js的传参数据中 # 结论:此案例中无法使用xpath解析,因为解析出来的html元素中不存在目标图片路径,xpath解析内容为空 # 2.使用正则匹配 # 找到js中存在的目标图片的路径,因为此时js代码也是属于响应内容的文本之一,可以使用正则表达式进行匹配。 # 编写正则表达式,采用compile方法匹配,参数1:正则表达式,参数2:匹配包括换行在内的所有字符 # p = re.compile('"thumbURL":"(.*?)"',re.S) # link_list = p.findall(html) # 直接使用findall() link_list = re.findall('"thumbURL":"(.*?)"',html) # 使用search()方法 # link_list = re.search('"thumbURL":"(.*?)"',html).group(1) # # 验证是否获取到url # print(link_list) # link_list: ['xxx.jpg','xxx.jpg'] #------第四步:对目标图片发起请求并将响应内容进行持久化存储 # 1.创建图片保存路径,保存图片到本地 directory = '/home/anwc/桌面/{}/'.format(word) #os.path.exists(directory)表示目录存在 #如果目录不存在(即先判断是否已存在目标目录) if not os.path.exists(directory): # 创建空目录并命名 os.makedirs(directory) # 2.循环的对目标图片发起请求获得响应 for link in link_list: # 请求图片获得响应 html = requests.get(url=link, headers=headers).content # 拼接我们想要的图片文件名(包含路径) filename = directory + '{}.jpg'.format(link[-24:-15]) # 写入文件 with open(filename, 'wb') as f: f.write(html) f.close() print(filename, '下载成功') -
面向对象编程
# -*- encoding: utf-8 -*- ''' @File : demo04_BaiduImageSpider_OOP.py @Time : 2020/09/09 10:01:20 @Author : 安伟超 @Version : 1.0 @Contact : awc19930818@outlook.com @github : https://github.com/La0bALanG @requirement: ''' import threading import requests from urllib import parse import re import os from lxml import etree class BaiduImageSpider(object): ''' 面向对象思路: 1.拆分功能细节。整体程序可拆分为: 1.发请求获得页面 2.解析页面 3.持久化存储(写入文件保存) 2.结合开闭原则,封装功能方法为私有方法,对外提供统一公共接口 3.采用单例模式:假设本爬虫程序在多个时间、不同情况下多次使用,单例模式实现只创建一个对象,提升性能避免内存占用过高。 ''' _instance_lock = threading.Lock() #单例模式实现:__new__方法 def __new__(cls, *args, **kwargs): if not hasattr(BaiduImageSpider, '_instance'): with BaiduImageSpider._instance_lock: if not hasattr(BaiduImageSpider, '_instance'): BaiduImageSpider._instance = object.__new__(cls) return BaiduImageSpider._instance def __init__(self): self.__url = 'https://image.baidu.com/search/index?tn=baiduimage&word={}' self.__headers = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36' } #设置只读属性 @property def url(self): return self.__url @property def headers(self): return self.__headers def __get_html(self,url): return requests.get(url=url, headers=self.__headers).text def __parse_html(self,html): return re.findall('"thumbURL":"(.*?)"', html) def __download_image(self,url): return requests.get(url=url,headers=self.__headers).content def __save_html(self,directory,data): # os.path.exists(directory)表示目录存在 # 如果目录不存在(即先判断是否已存在目标目录) if not os.path.exists(directory): # 创建空目录并命名 os.makedirs(directory) # 2.循环的对目标图片发起请求获得响应 for link in data: # 请求图片获得响应 img = self.__download_image(link) # 拼接我们想要的图片文件名(包含路径) filename = directory + '{}.jpg'.format(link[-24:-15]) # 写入文件 with open(filename, 'wb') as f: f.write(img) f.close() def display(self,word): directory = '/home/anwc/桌面/{}/'.format(word) self.__save_html(directory,self.__parse_html(self.__get_html(self.__url.format(parse.quote(word))))) def test(): word = input('请输入明星>>>:') BaiduImageSpider.display(word) if __name__ == '__main__': test()




