
Python爬虫笔记2:爬虫基础概念
作者:Barranzi_
个人github主页:[github](https://github.com/La0bALanG)
个人邮箱:awc19930818@outlook.com
新时代的铁饭碗:一辈子不管走到哪里都有饭吃(还能吃上热乎的)。——佚名
免责声明:
本系列笔记撰写初衷就是为了分享个人知识以及个人学习历程中的感悟及思考,所涉及到的内容`仅供学习与交流`,请勿用作`非法或商业用途`!由此引发的任何法律纠纷`后果自负`,与作者本人无关!
版权声明:
未经作者本人授权,禁止转载!请尊重原创!

注:本文所有代码、案例测试环境:1.Linux -- 系统版本:Ubuntu20.04 LTS 2.windows -- 系统版本:WIN10 64位家庭版
爬虫基本概念
定义
网络蜘蛛、网络机器人,抓取网络数据的程序。其实就是用Python程序模仿人点击浏览器并访问网站,而且模仿的越像越好,让Web站点无法发现你不是人
使用爬虫的目的
- 公司项目测试数据
- 公司业务部门及其他部门所需数据
- 数据分析
爬虫的特点
- 爬虫只是一种技术的分支,主要面向网站,网页应用等的数据爬取,是众多数据获取途径中成本最低,效率最高的方式
- 爬虫工程师理论上归属软件开发工程师的一种
- 从技术层面来说,“万维网上一切数据皆可爬”,但实际应用过程中必须遵守国家相关法律法规,遵守各大企业机构制定的协议。
企业获取数据的方式
- 公司自有数据
- 人工采集获取
- 第三方数据平台
- 爬虫爬取
使用Python做爬虫的优势
- Python :请求模块、解析模块丰富成熟,强大的Scrapy网络爬虫框架
- PHP :对多线程、异步支持不太好
- JAVA:代码笨重,代码量大
- C/C++:虽然效率高,但是代码成型慢
爬虫分类
根据使用场景,网络爬虫可分为
通用爬虫和聚焦爬虫
- 通用网络爬虫:搜索引擎使用,遵守robots协议
- 聚焦网络爬虫 :自己写的爬虫程序
通用爬虫
介绍
通用网络爬虫是搜索引擎的关键组成部分,其主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像或备份。
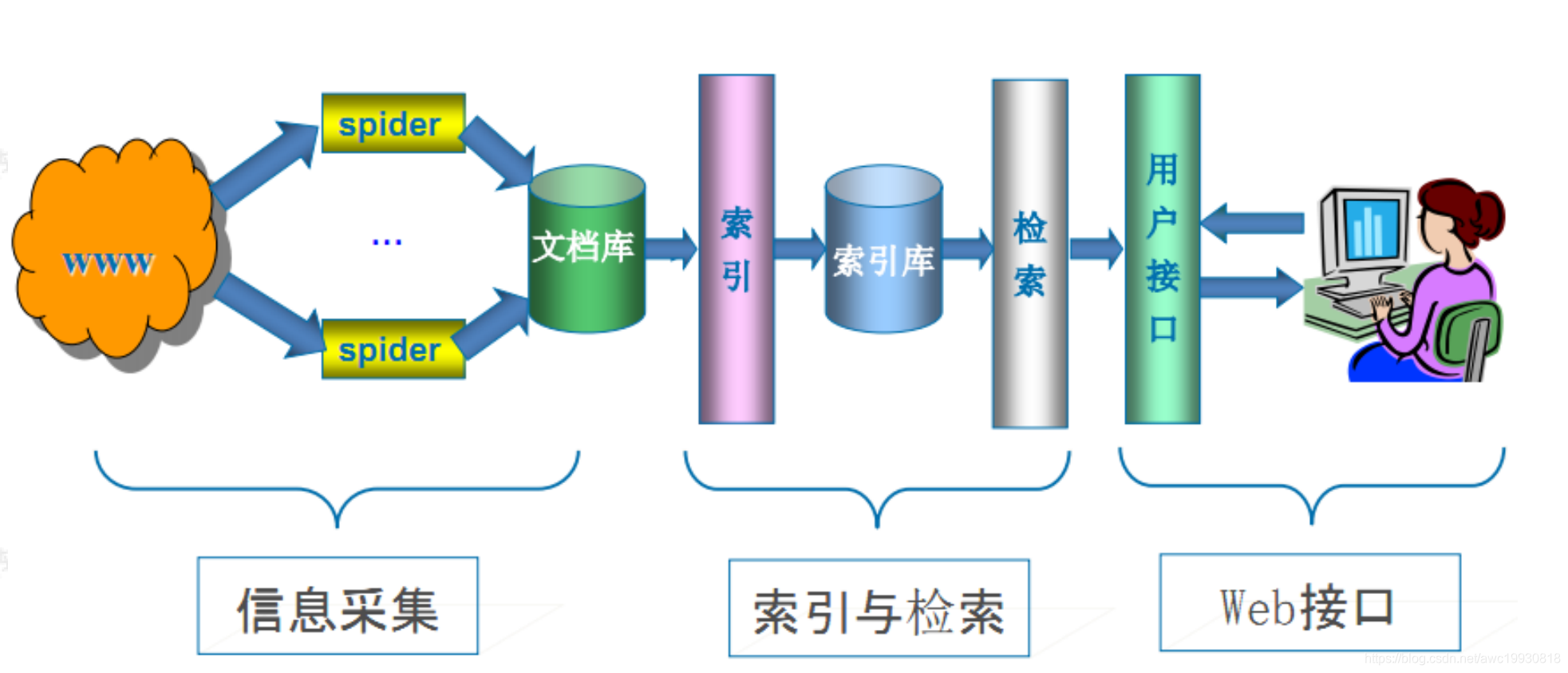
通用搜索引擎(Search Engine)工作流程
通用网络爬虫主要工作就是从互联网中搜集网页,采集信息。这些被采集到的网页信息用于搜索引擎建立索引从而提供支持,它决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的优劣直接影响着搜索引擎的效果。
一般的,通用搜索引擎大致的工作步骤如下:
1.抓取网页。
1.首先选取一部分的种子URL,将这些URL放入待抓取URL队列;
2.取出待抓取的URL,解析DNS得到主机的IP,并将URL对应的网页下载下来,存储进已下载网页库中,并将这些URL放进已抓取URL队列;
3.分析已抓取URL队列中的URL,分析其内部包含的其他URL,并且一并将URL放入待抓取的URL队列,继而实现下一个循环…
搜索引擎如何获取一个新网站的URL:
1.新网站向搜索引擎主动提交网址。例如百度:https://ziyuan.baidu.com/linksubmit/url
2.在其网站上设置新网站的外链(尽可能处理搜索引擎爬虫爬取的范围)
3.搜索引擎和DNS解析服务商(比如DNSPod等)合作,新网站域名将被迅速抓取。 robots协议:也叫作爬虫协议,机器人协议等,全称为“网络爬虫排除标准(Robots Exclusion Protocol)”,网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。例如:
淘宝网:https://www.taobao.com/robots.txt 腾讯网:http://www.qq.com/robots.txt
2.数据存储
搜索引擎通过爬虫爬取到的页面,将数据存入原始页面数据库。其中的页面数据与用户浏览器得到的HTML完全一致。
搜索引擎蜘蛛在爬取页面时,也做一定的重复内容检测,一旦遇到访问权重很低的网站上有大量抄袭、采集或者复制的内容,很可能就不在运行。
3.预处理
搜索引擎将爬虫抓取回来的页面,进行各种步骤的预处理。常见的预处理步骤如下
1.提取文字
2.中文分词
3.消除噪音(比如版权声明,广告等)
4.索引处理
5.链接关系计算
6.特殊文件处理
4.提供检索,网站排名等具体实质服务。
搜索引擎在对信息进行组织和处理后,为用户提供关键字检索服务,将用户检索相关的信息展示给用户。
同时还会根据页面的PageRank值(链接的访问量排名)来进行网站排名,以及其他的各种可能提供的服务。
通用搜索引擎大致工作流程图示如下:
聚焦爬虫
聚焦爬虫是指面向特定需求的网络爬虫程序,其与通用搜索引擎爬虫的区别在于:聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证之抓取与需求相关的网页信息。
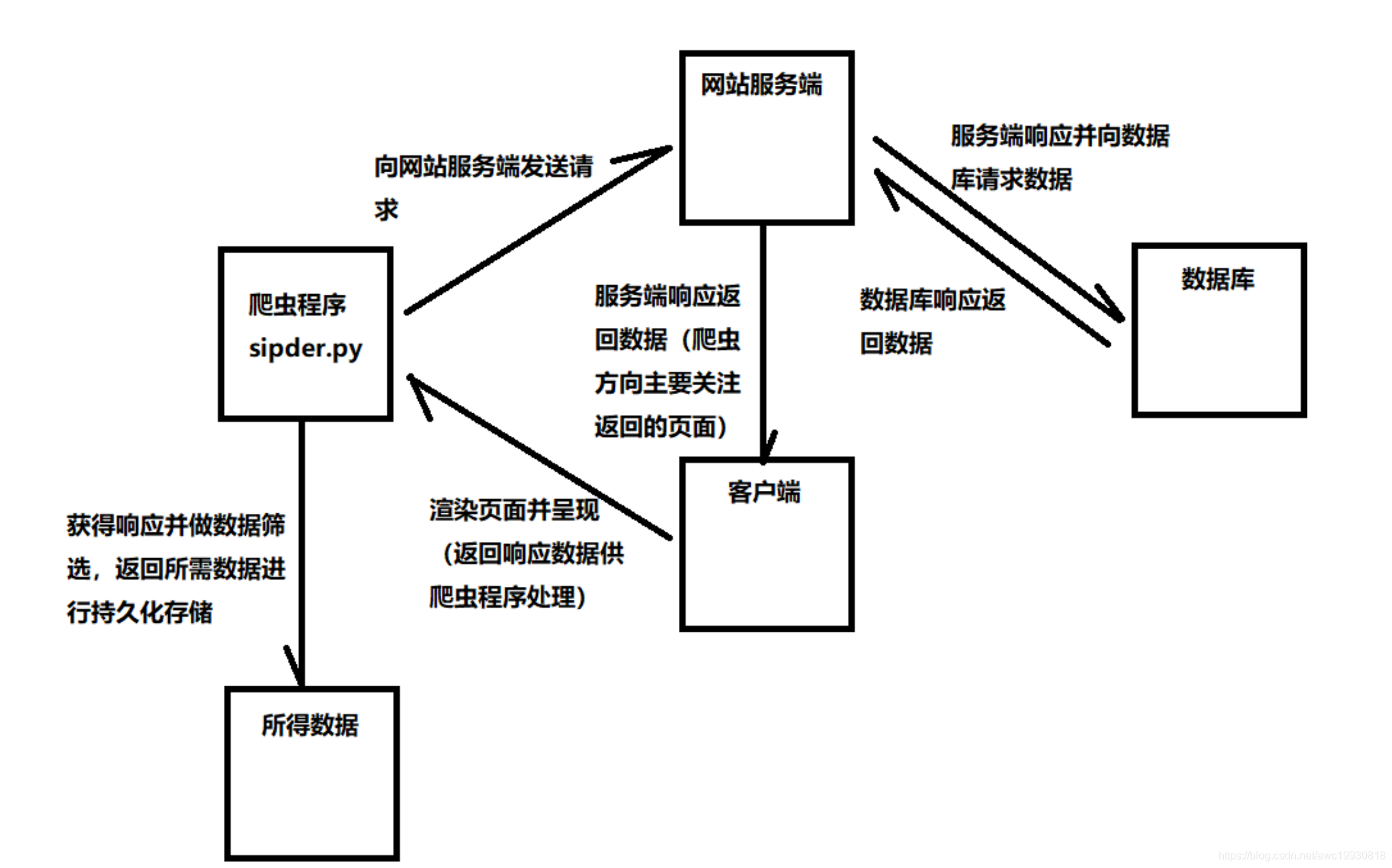
爬虫固定套路(语义层面概括)
- 分析页面
- 分析网站URL规律,确定具体的URL
- 分析网页结构,确定目标数据具体所在位置
- 数据存在于响应的页面主体(最理想的位置,无需进行抓包分析)
- 数据不在响应的页面主体:
- 使用自带的浏览器控制台进行抓包分析,突破AJAX异步加载确定数据位置
- 使用fiddler抓包分析
- 向网站发起请求获得响应数据
- 对响应得到的数据进行筛选(也叫做解析或提取)
- 直接得到所需数据,清洗入库(通常称为持久化存储)
- 页面中存在其他需要继续抓取的URL地址,重复第三步,如此循环
爬虫固定套路图示注解
HTTP/HTTPS协议
HTTP协议简介
概念:通信计算机双方必须共同遵守的一种约定,只有遵守这个约定,计算机之间才能进行通信。
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是一种发布和接受HTML页面的方法。
HTTPS (全称:Hyper Text Transfer Protocol over SecureSocket Layer),是以安全为目标的 HTTP 通道,在HTTP的基础上通过传输加密和身份认证保证了传输过程的安全性 。HTTPS 在HTTP 的基础下加入SSL 层,HTTPS 的安全基础是 SSL,因此加密的详细内容就需要 SSL。 HTTPS 存在不同于 HTTP 的默认端口及一个加密/身份验证层(在 HTTP与 TCP 之间)。这个系统提供了身份验证与加密通讯方法。它被广泛用于万维网上安全敏感的通讯,例如交易支付等方面 。
HTTPS是加密之后的HTML,说白了就是安全版的HTML,其加入的SSL层保证了数据传输的安全性及可靠性。
SSL(Secure Sockets Layer安全套接层)主要用于web的安全传输协议,在传输层对网络连接进行加密,保证在internet上的数据传输安全。
HTTP请求与响应
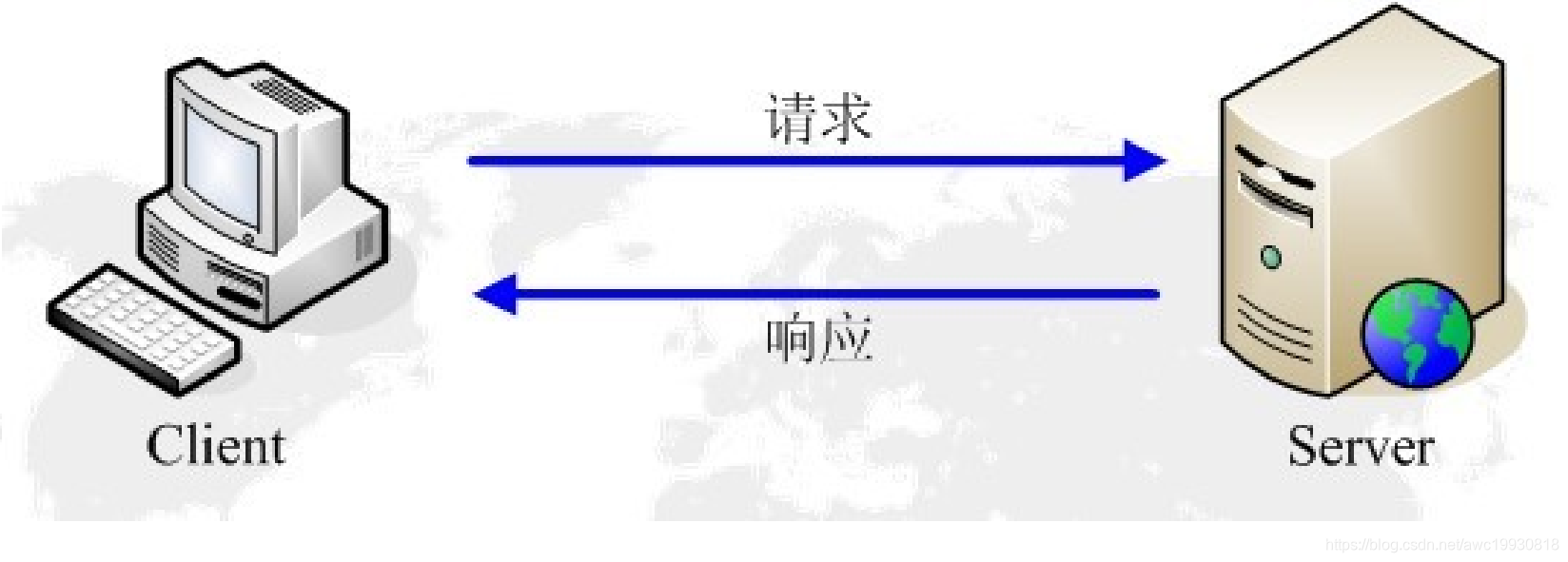
HTTP通信由两部分组成: 1.客户端请求消息 2.服务器响应消息
大致通信流程如下:
- 当用户在浏览器的地址栏中输入一个URL并按下回车键后,浏览器会向HTTP服务器发送HTTP请求。HTTP常用的请求方式为get请求方法和post请求方法。
- 当我们在浏览器输入URL:https://www.baidu.com的时候,浏览器发送一个request请求去获取该网站的html文件,服务器把response文件对象返回给浏览器
- 浏览器分析response中的html,分析过程中发现其引用些许外部文件,如样式表,js文件,图片,音频,视频等,浏览器会自动再次发送request去获取对应的外部文件。
- 当所有的文件都下载,加载完毕后,网页会根据html语法结构,完整的渲染出最终页面。
统一资源定位符:URL
URL:统一资源定位符,用于完整的描述internet上网页和其他资源的地址的一种标识方法。
URL基本格式如下:
协议://主机:[端口号]/路径/?[请求or查询参数]…/[#锚点]
- 协议:scheme,指的就是HTTP或HTTPS
- 主机:host,服务器的IP地址或域名
- 端口号:port,服务器端口
- 路径:path,访问资源的路径
- 请求参数:query_string,发送给http服务器的数据
- 查询参数:parmas,参数的一种常见形式
- auther:锚点,用于页面内跳转
请求内容
-
请求行
由请求方式+URL+协议版本组成
例如:
GET https://www.baidu.com/aaa/bbb/?aa=xx HTTP/1.1 -
请求头:客户端向服务器发送请求的补充说明,不可缺少。
- HOST:主机,即请求地址
- User-Agent:客户端使用的操作系统和浏览器的名称和版本
- Content-Length:发送给HTTP服务器数据的长度。
- Content-Type:参数的数据类型
- Cookie:发送给HTTP 服务器的cookie值
- Accept:浏览器接受的媒体类型
- Accept-Language:浏览器自己接收的语言
- Accept-Charset:自己接收的字符集
-
请求体
一般携带的请求参数。只有当请求方式为POST时才有请求体,GET的请求体直接包含在了URL部分。
-
请求内容举例:
GET / HTTP/1.1 Host: www.baidu.com Connection: keep-alive Cache-Control: max-age=0 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHT Sec-Fetch-Mode: navigate Sec-Fetch-User: ?1 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,imag Sec-Fetch-Site: same-origin Referer: https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd= Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9 Cookie:BIDUPSID=4049831E3DB8DE890DFFCA6103FF02C1;
请求方法
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | GET | 请求指定的页面信息,并返回实体主体 |
| 2 | HEAD | 类似于get请求,只不过返回的响应中没有具体的内容,用于获取请求头 |
| 3 | POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件),数据被包含在请求体中。POST请求可能会导致新的资源建立或已有资源的修改 |
| 4 | PUT | 从客户端向服务器传送的数据取代指定的文档内容 |
| 5 | DELETE | 请求服务器删除指定的页面 |
| 6 | CONNECT | HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器 |
| 7 | OPTIONS | 允许客户端查看服务器的性能 |
| 8 | TRACE | 回显服务器收到的请求,主要用于测试 |
响应内容
-
响应行:由“HTTP 版本号 + 响应状态码 + 状态说明”组成。
例如:HTTP/1.1 200 OK
-
响应头:与请求头对应
-
响应体:这才是真正的响应数据,这些数据其实就是网页的HTML源码
响应内容举例:
HTTP/1.1 200 OK Bdpagetype: 1 Bdqid: 0xdbeb11ea000cfef4 Cache-Control: private Connection: keep-alive Content-Encoding: gzip Content-Type: text/html Cxy_all: baidu+642857607c537ed21fa04bcfb54ff6ee Date: Thu, 02 Jan 2020 06:32:55 GMT Expires: Thu, 02 Jan 2020 06:32:51 GMT Server: BWS/1.1 Set-Cookie: delPer=0; path=/; domain=.baidu.com Set-Cookie: BDSVRTM=6; path=/ Set-Cookie: BD_HOME=0; path=/ Set-Cookie: H_PS_PSSID=1448_21096_30210_30283_30504; path=/; domain=.baidu.co Strict-Transport-Security: max-age=172800 Traceid: 1577946775028760116215846779410554093300 Vary: Accept-Encoding X-Ua-Compatible: IE=Edge,chrome=1 Transfer-Encoding: chunked
响应状态码
响应状态码有 1XX、2XX、3XX、4XX、5XX、5XX。
- 1XX 提示信息 - 表示请求已被成功接收,继续处理
- 2XX 成功 - 表示请求已被成功接收,理解,接受
- 3XX 重定向 - 要完成请求必须进行更进一步的处理
- 4XX 客户端错误 - 请求有语法错误或请求无法实现
- 5XX 服务器端错误 - 服务器未能实现合法的请求响应头
网站的类型
1.静态网站:页面数据一次请求时全部加载直接返回至响应数据,局部操作时浏览器跟随刷新;
2.动态网站:页面数据多次请求时跟随每一次请求进行异步刷新,局部操作时浏览器不跟随刷新
动态网站的特征
- 需要登陆或验证码(常见的图形码,滑块码,拼图码,四位随机验证码,短信邮箱验证码等)
- 站点IP限制:同一个地址在短时间内大量请求的话会限制其请求次数——封IP
- 数据屏蔽:80%的动态网站是无法直接从页面的响应数据中检索目标数据的,大部分需要突破AJAX异步加载及js逆向进行检索,小部分直接采用反爬策略隐藏数据。
- 网站动态加载:跟随每一次请求操作在不刷新页面的情况下使用AJAX异步加载数据。
反爬虫机制(网站采用的防止爬虫程序请求数据的方式)
- 封IP:监控短时间内同一地址的请求次数过大
- 登录及验证码:对于监控后封IP之后短时间内继续的大量请求,要求登陆或验证码通过验证之后才能继续进行。
- 健全账号体制:即核心数据只能通过账号登录后才能进行访问。
- 动态加载数据:数据通过js进行加载,增加网站分析难度。
- …
反反爬策略(针对网站常见的反爬虫机制设计的常用反制措施,以达到能顺利获取数据的目的)
- 伪造请求头(伪装浏览器):故意告诉浏览器我不是爬虫程序我是浏览器。
- 代理IP访问:针对同一时间内大量请求网站数据遭到封IP,使用代理IP不断更换请求地址,迷惑网站,躲过反制措施。
- 请求过于频繁会触发验证码,则模拟用户操作,限制爬虫请求次数及频率,降低验证码机制的风险
- 使用对应的验证码识别手段通过网站验证
- 使用第三方工具完全模拟浏览器操作(selenium+webdriver)
- …
网站为何要反制爬虫
- 保护企业自有数据的安全。
- 保护企业服务器正常稳定运行。
- 版权等其他原因。
爬虫 VS 网站数据安全 矛 盾
爬虫请求模块——urllib.request
模块及导入
1、模块名:urllib.request
2、导入方式:
1、import urllib.request
2、from urllib import request
常用方法详解
urllib.request.urlopen
- 作用 向网站发起请求并获取响应对象
- 语法
变量名 = urllib.requrest.urlopen(url,timeout)
- 参数
1.url:需要爬取的网站的URL地址
2.timeout:设置等待超时时间,指定时间内未得到响应则抛出超时异常
- 示例:最简单的爬虫程序——输入百度地址(‘http://www.baidu.com’),得到百度首页的响应内容
import urllib.request
# urlopen() : 向URL发请求,返回响应对象,保存变量于response
response=urllib.request.urlopen('http://www.baidu.com/')
# 提取响应内容:响应对象调用read方法读取对应的响应内容,因为得到的是字节串,所以解码为字符串,注意设置编码方式utf-8
html = response.read().decode('utf-8')
# 打印响应内容
print(html)
- 响应对象(response)方法
1、bytes = response.read() # read()得到结果为 bytes 数据类型
2、string = response.read().decode() # decode() 转为 string 数据类型
3、url = response.geturl() # 返回实际数据的URL地址
4、code = response.getcode() # 返回HTTP响应码
# 补充
5、string.encode() # bytes -> string
6、bytes.decode() # string -> bytes
思考:网站是如何判断是人类正常访问还是爬虫程序访问?接下来通过一段简单测试代码查看:
import urllib.request
# 向测试网站:http://httpbin.org/get发送请求,获取响应对象并查看请求头
response = urllib.request.urlopen('http://httpbin.org/get')
# 响应对象读取响应内容并转为字符串显示
html = response.read().decode('utf-8')
print(html)
====================================================================================
得到的响应结果如下:
/home/anwc/anaconda3/bin/python /home/anwc/文档/文档、代码杂七八/code_demo.py
{
"args": {},
"headers": {
"Accept-Encoding": "identity",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.6",
"X-Amzn-Trace-Id": "Root=1-5eb51309-98987ec462d6a7fe19b38aea"
},
"origin": "27.18.84.11",
"url": "http://httpbin.org/get"
}
Process finished with exit code 0
通过响应内容我们发现:请求头中User-Agent竟然是:Python-urllib/3.6
因此我们需要重构User-Agent,发请求时带着User-Agent过去,但是urlopen()方法不支持重构User-Agent!
那我们怎么办?请看下面的方法!!!
urllib.request.Request
- 作用 创建请求对象(包装请求,重构User-Agent,使程序更像正常人类请求)
- 语法
response = urllib.request.Request(url = url,headers = headers)
- 参数
1、url:请求的URL地址
2、headers:添加请求头(爬虫和反爬虫斗争的第一步)
- 使用流程
1、构造请求对象(重构User-Agent)
2、发请求获取响应对象(urlopen)
3、获取响应对象内容
- 示例:向测试网站发起请求,构造请求头并从响应对象中确认请求头信息
from urllib import request
# 定义常用变量
url = 'http://httpbin.org/get'
headers = {'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'}
# 1.创建请求对象
req = request.Request(url=url,headers=headers)
# 2.获取响应对象
resp = request.urlopen(req)
# 3.提取响应内容
html = resp.read().decode()
print(html)
==================================================================================
得到的响应信息如下:
/home/anwc/anaconda3/bin/python /home/anwc/文档/文档、代码杂七八/code_demo.py
{
"args": {},
"headers": {
"Accept-Encoding": "identity",
"Host": "httpbin.org",
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36",
"X-Amzn-Trace-Id": "Root=1-5eb515fc-67a09f30af080940ecd78190"
},
"origin": "27.18.84.11",
"url": "http://httpbin.org/get"
}
Process finished with exit code 0
爬虫请求模块——requests
安装
- Linux
sudo pip3 install requests
- Windows
# 方法一
进入cmd命令行 :python -m pip install requests
# 方法二
右键管理员进入cmd命令行 :pip install requests
requests.get()
- 作用
# 向网站发起请求,并获取响应对象
res = requests.get(url,headers=headers)
- 参数
1、url :需要抓取的URL地址
2、headers : 请求头
3、timeout : 超时时间,超过时间会抛出异常
- 响应对象(res)属性
1、encoding :响应字符编码
res.encoding = 'utf-8'
2、text :字符串
3、content :字节流
4、status_code :HTTP响应码
5、url :实际数据的URL地址
- 非结构化数据保存
with open('xxx.jpg','wb') as f:
f.write(res.content)
requests.get()参数
查询参数-params
-
参数类型
字典,字典中键值对作为查询参数
-
使用方法
1、res = requests.get(url,params=params,headers=headers)
2、特点:
* url为基准的url地址,不包含查询参数
* 该方法会自动对params字典编码,然后和url拼接
- 示例
import requests
baseurl = 'http://tieba.baidu.com/f?'
params = {
'kw' : '赵丽颖吧',
'pn' : '50'
}
headers = {'User-Agent' : 'Mozilla/4.0'}
# 自动对params进行编码,然后自动和url进行拼接,去发请求
res = requests.get(url=baseurl,params=params,headers=headers)
res.encoding = 'utf-8'
print(res.text)
Web客户端验证参数-auth
- 作用及类型
1、针对于需要web客户端用户名密码认证的网站
2、auth = ('username','password')
SSL证书认证参数-verify
-
适用网站及场景
- 适用网站: https类型网站但是没有经过 证书认证机构 认证的网站
- 适用场景: 抛出 SSLError 异常则考虑使用此参数
-
参数类型
-
verify=True(默认) : 检查证书认证 -
verify=False(常用): 忽略证书认证 -
示例:
response = requests.get( url=url, params=params, headers=headers, verify=False )
-
代理参数-proxies
- 定义: 代替你原来的IP地址去对接网络的IP地址。
- 作用: 隐藏自身真实IP,避免被封。
requests.post()参数
-
适用场景
Post类型请求的网站
-
参数-data
response = requests.post(url,data=data,headers=headers) # data :post数据(Form表单数据-字典格式) -
适用场景
form表单提交数据时或向网站请求其他类型的数据时。
案例:百度图片搜索爬取
参见代码:Spider_Codes/demo01_BaiduImageSpider_simple.py
参见代码:Spider_Codes/demo01_BaiduImageSpider_OOP.py(面向对象封装)
URL地址编码模块——urllib.parse
模块及导入
- 模块
# 模块名
urllib.parse
# 导入
import urllib.parse
from urllib import parse
- 作用 给URL地址中查询参数进行编码
编码前:https://www.baidu.com/s?wd=美女
编码后:https://www.baidu.com/s?wd=%E7%BE%8E%E5%A5%B3
常用方法详解
urllib.parse.urlencode({dict})
-
URL地址中查询一个参数
示例:给定一个查询参数并将其进行编码
import urllib.parse
# 给定一个查询参数
query_str = {'wd':'美眉'}
# 调用urlencode方法将其编码
result = urllib.parse.urlencode(query_str)
print(result)
-
URL地址中多个查询参数
示例:给定多个查询参数并将其进行编码
from urllib import parse
params = {
'wd':'美眉',
'pn':'50'
}
params = parse.urlencode(params)
url = 'http://www.baidu.com/s?{}'.format(params)
print(url)
- 拼接URL地址的3种方式
# 1、字符串相加
baseurl = 'http://www.baidu.com/s?'
params = 'wd=%E7XXXX&pn=20'
url = baseurl + params
# 2、字符串格式化(占位符)
params = 'wd=%E7XXXX&pn=20'
url = 'http://www.baidu.com/s?%s'% params
# 3、format()方法
url = 'http://www.baidu.com/s?{}'
params = 'wd=#E7XXXX&pn=20'
url = url.format(params)
- 示例:在百度种输入要搜索的内容,把响应内容保存到本地文件
from urllib import request,parse
# 拼接URL
my_input = input('请输入你要搜索的内容:')
parmas = parse.urlencode({'wd':my_input})
url = 'http://www.baidu.com/s?{}'.format(parmas)
# 创建请求头
headers = {
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
# 创建请求对象
req = request.Request(url=url,headers=headers)
# 获取响应对象并读取响应内容
response = request.urlopen(req)
result = response.read().decode()
# 将响应内容写入文件
filename = my_input + '.html'
with open(filename,'w') as f:
f.write(result)
quote(str)编码
- 示例:对单个字符串进行编码
from urllib import parse
str1 = '美眉'
print(parse.quote(str1))
- 示例:针对上文示例,将URL编码改为使用quote方法实现
from urllib import request,parse
# 拼接URL
my_input = input('请输入你要搜索的内容:')
parmas = parse.quote(my_input)
url = 'https://www.baidu.com/s?wd={}'.format(parmas)
# 创建请求头
headers = {
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
# 创建请求对象
req = request.Request(url=url,headers=headers)
# 获取响应对象并读取响应内容
response = request.urlopen(req)
result = response.read().decode()
# 将响应内容写入文件
filename = my_input + '.html'
with open(filename,'w') as f:
f.write(result)
unquote(str)解码
- 示例:对单个字符进行解码
from urllib import parse
string = '%E7%BE%8E%E5%A5%B3'
result = parse.unquote(string)
print(result)
re正则表达式
re模块使用流程
- 方法一
r_list=re.findall('正则表达式',html,re.S)
- 方法二
# 1、创建正则编译对象
pattern = re.compile(r'正则表达式',re.S)
r_list = pattern.findall(html)
正则表达式元字符
| 元字符 | 含义 |
|---|---|
| . | 任意一个字符(不包括\n) |
| \d | 一个数字 |
| \s | 空白字符 |
| \S | 非空白字符 |
| [] | 包含[]内容 |
| * | 出现0次或多次 |
| + | 出现1次或多次 |
思考:请写出匹配任意一个字符的正则表达式?
import re
# 方法一
pattern = re.compile('.',re.S)
# 方法二
pattern = re.compile('[\s\S]')
贪婪匹配(默认)
- 在整个表达式匹配成功的前提下,尽可能多的匹配
- 表示方式: .
非贪婪匹配
-
在整个表达式匹配成功的前提下,尽可能少的匹配
-
表示方式:.?
示例:正则匹配演示
import re
html = '''
<div><p>九霄龙吟惊天变</p></div>
<div><p>风云际会浅水游</p></div>
'''
# 贪婪匹配
p = re.compile('<div><p>.*</p></div>',re.S)
r_list = p.findall(html)
# 非贪婪匹配
p = re.compile('<div><p>.*?</p></div>',re.S)
r_list = p.findall(html)
正则表达式分组
-
作用
在完整的模式中定义子模式,将每个圆括号中子模式匹配出来的结果提取出来
-
示例:分组演示
import re
s = 'A B C D'
p1 = re.compile('\w+\s+\w+')
print(p1.findall(s))
# 结果: ???
p2 = re.compile('(\w+)\s+\w+')
print(p2.findall(s))
# 结果: ???
p3 = re.compile('(\w+)\s+(\w+)')
print(p3.findall(s))
# 结果: ???
- 分组总结
1、在网页中,想要什么内容,就加()
2、先按整体正则匹配,然后再提取分组()中的内容
如果有2个及以上分组(),则结果中以元组形式显示 [('小区1','500万'),('小区2','600万'),()]
-
练习
页面结构如下:
# <div class="animal">.*?title="(.*?)".*?
<div class="animal">
<p class="name">
<a title="Tiger"></a>
</p>
<p class="content">
Two tigers two tigers run fast
</p>
</div>
<div class="animal">
<p class="name">
<a title="Rabbit"></a>
</p>
<p class="content">
Small white rabbit white and white
</p>
</div>
从以上html代码结构中完成如下内容信息的提取:
# 问题1
[('Tiger',' Two...'),('Rabbit','Small..')]
# 问题2
动物名称 :Tiger
动物描述 :Two tigers two tigers run fast
***************************************
动物名称 :Rabbit
动物描述 :Small white rabbit white and white
- 代码实现
import re
html = '''
<div class="animal">
<p class="name">
<a title="Tiger"></a>
</p>
<p class="content">
Two tigers two tigers run fast
</p>
</div>
<div class="animal">
<p class="name">
<a title="Rabbit"></a>
</p>
<p class="content">
Small white rabbit white and white
</p>
</div>
'''
p = re.compile('<div class="animal">.*?<a title="(.*?)"'
'.*?<p class="content">(.*?)</p>',re.S)
r_list = p.findall(html)
# 第1步: r_list: [('Tiger','\n\t\tTwo tigers'),()]
print(r_list)
# 第2步
for r in r_list:
print('动物名称:',r[0].strip())
print('动物描述:',r[1].strip())
print('*' * 50)
==========================================================================================
运行结果:
/home/anwc/anaconda3/bin/python /home/anwc/文档/文档、代码杂七八/code_demo.py
[('Tiger', '\n\t\tTwo tigers two tigers run fast\n '), ('Rabbit', '\n\t\tSmall white rabbit white and white\n ')]
动物名称: Tiger
动物描述: Two tigers two tigers run fast
**************************************************
动物名称: Rabbit
动物描述: Small white rabbit white and white
**************************************************
Process finished with exit code 0
==========================================================================================
常见方法总结:
1. strip() - 去掉左右两侧的空白
2. split()
'东方美景|200万|23层'.split('|')
['东方美景','200万','23层']
3. replace()
'霸王别姬 大话西游 '.replace(' ',' ')
结果: '霸王别姬 大话西游'
4. startswith()
5. endswith()
if 'xxx.zip'.endswith('.zip'):
开始抓取 xxx.zip 文件到本地
6. join()
'\n'.join(['第一章:大圣娶亲','第二章:月光宝盒','第三章:美人鱼'])
'第一章:大圣娶亲\n第二章xxx'
7. 切片
爬虫数据解析模块——re模块
re模块支持的正则语法
"."
"^"
"$"
"*"
"+"
"?"
*?,+?,??
{m,n}
{m,n}?
"\\"
[]
"|"
(...)
(?aiLmsux)
(?:...)
(?P<name>...)
(?P=name)
(?#...)
(?=...)
(?!...)
(?<=...)
(?<!...)
(?(id/name)yes|no)
re模块内置的常用方法
| 方法 | 描述 | 返回值 |
|---|---|---|
| comple(re,flags) | 根据包含正则表达式的字符串创建模式对象 | re对象 |
| search(re,flags) | 在字符串中查找 | 第一个匹配到的对象或者None |
| match(re,flags) | 在字符串的开始处匹配查找 | 在字符串开头匹配到的对象或者None |
| split() | 根据模式的匹配项来分割字符串 | 分割后的字符串列表 |
| findall(re,flags) | 列出字符串中模式的所有匹配项 | 所有匹配到的字符串列表 |
| sub() | 将字符串中所有的匹配项用repl替换 | 完成替换后的新字符串 |
常见的flag匹配模式:
| 匹配模式 | 描述 |
|---|---|
| re.A | ASCII字符模式 |
| re.I | 使匹配对大小写不敏感,也就是不区分大小写 |
| re.L | 做本地化识别匹配 |
| re.M | 多行匹配,影响^和 $ |
| re.S | 使.这个通配符能够匹配包括换行在内的所有字符,针对多行匹配 |
| re.U | 根据unicode字符集解析字符,这个标志影响\w,\W,\b,\B |
| re.X | 该标志通过给予你更灵活的格式以便将正则表达式写的更易于理解 |
案例:百度贴吧数据抓取
参见代码:Spider_Codes/demo02_baidutieba_simple.py
参见代码:Spider_Codes/demo02_baidutieba_OOP.py(面向对象封装)
案例:猫眼电影top100抓取
参见代码:Spider_Code/demo03_MaoYanMovie_OOP.py
程序运行结果:
anwc@anwc:~/文档/文档、代码杂七八$ python3 demo_spider_maoyan.py
程序开始执行,即将爬取top100榜单信息,每10条将间隔三到五秒继续...
{'name': '活着', 'star': '主演:葛优,巩俐,牛犇', 'time': '1994-05-17'}
{'name': '钢琴家', 'star': '主演:艾德里安·布洛迪,艾米莉娅·福克斯,米哈乌·热布罗夫斯基', 'time': '2002-05-24'}
{'name': '勇敢的心', 'star': '主演:梅尔·吉布森,苏菲·玛索,帕特里克·麦高汉', 'time': '1995-05-18'}
{'name': '阿飞正传', 'star': '主演:张国荣,张曼玉,刘德华', 'time': '2018-06-25'}
{'name': '射雕英雄传之东成西就', 'star': '主演:张国荣,梁朝伟,张学友', 'time': '1993-02-05'}
{'name': '爱·回家', 'star': '主演:俞承豪,金艺芬,童孝熙', 'time': '2002-04-05'}
{'name': '初恋这件小事', 'star': '主演:马里奥·毛瑞尔,平采娜·乐维瑟派布恩,阿查拉那·阿瑞亚卫考', 'time': '2012-06-05'}
{'name': '泰坦尼克号', 'star': '主演:莱昂纳多·迪卡普里奥,凯特·温丝莱特,比利·赞恩', 'time': '1998-04-03'}
{'name': '迁徙的鸟', 'star': '主演:雅克·贝汉,Philippe Labro', 'time': '2001-12-12'}
{'name': '蝙蝠侠:黑暗骑士', 'star': '主演:克里斯蒂安·贝尔,希斯·莱杰,阿伦·伊克哈特', 'time': '2008-07-14'}
{'name': '恐怖直播', 'star': '主演:河正宇,李璟荣,李大卫', 'time': '2013-07-31'}
{'name': '我爱你', 'star': '主演:宋在浩,李顺才,尹秀晶', 'time': '2011-02-17'}
{'name': '大闹天宫', 'star': '主演:邱岳峰,毕克,富润生', 'time': '1965-12-31'}
{'name': '剪刀手爱德华', 'star': '主演:约翰尼·德普,薇诺娜·瑞德,黛安娜·威斯特', 'time': '1990-12-06'}
{'name': '甜蜜蜜', 'star': '主演:黎明,张曼玉,杜可风', 'time': '2015-02-13'}
{'name': '闻香识女人', 'star': '主演:阿尔·帕西诺,克里斯·奥唐纳,加布里埃尔·安瓦尔', 'time': '1992-12-23'}
{'name': '英雄本色', 'star': '主演:狄龙,张国荣,周润发', 'time': '2017-11-17'}
{'name': '三傻大闹宝莱坞', 'star': '主演:阿米尔·汗,黄渤,卡琳娜·卡普', 'time': '2011-12-08'}
{'name': '黑客帝国3:矩阵革命', 'star': '主演:基努·里维斯,雨果·维文,凯瑞-安·莫斯', 'time': '2003-11-05'}
{'name': '触不可及', 'star': '主演:弗朗索瓦·克鲁塞,奥玛·希,安娜·勒尼', 'time': '2011-11-02'}
{'name': '忠犬八公物语', 'star': '主演:仲代达矢,春川真澄,井川比佐志', 'time': '1987-08-01'}
{'name': '辩护人', 'star': '主演:宋康昊,郭度沅,吴达洙', 'time': '2013-12-18'}
{'name': '喜剧之王', 'star': '主演:周星驰,莫文蔚,张柏芝', 'time': '1999-02-13'}
{'name': '黄金三镖客', 'star': '主演:克林特·伊斯特伍德,李·范·克里夫,埃里·瓦拉赫 Eli Wallach', 'time': '1966-12-23'}
{'name': '这个杀手不太冷', 'star': '主演:让·雷诺,加里·奥德曼,娜塔莉·波特曼', 'time': '1994-09-14'}
{'name': '借东西的小人阿莉埃蒂', 'star': '主演:志田未来,神木隆之介,大竹忍', 'time': '2010-07-17'}
{'name': '大话西游之月光宝盒', 'star': '主演:周星驰,莫文蔚,吴孟达', 'time': '2014-10-24'}
{'name': '一一', 'star': '主演:吴念真,金燕玲,李凯莉', 'time': '2000-05-15'}
{'name': '窃听风暴', 'star': '主演:乌尔里希·穆埃,塞巴斯蒂安·科赫,马蒂娜·格德克', 'time': '2006-03-23'}
{'name': '楚门的世界', 'star': '主演:金·凯瑞,劳拉·琳妮,诺亚·艾默里奇', 'time': '1998(罗马尼亚)'}
{'name': '飞屋环游记', 'star': '主演:爱德华·阿斯纳,乔丹·长井,鲍勃·彼德森', 'time': '2009-08-04'}
{'name': '哈尔的移动城堡', 'star': '主演:倍赏千惠子,木村拓哉,美轮明宏', 'time': '2004-09-05'}
{'name': '上帝之城', 'star': '主演:亚历桑德雷·罗德里格斯,艾莉丝·布拉加,莱安德鲁·菲尔米诺', 'time': '2002(俄罗斯)'}
{'name': '美丽心灵', 'star': '主演:罗素·克洛,詹妮弗·康纳利,艾德·哈里斯', 'time': '2001-12-13'}
{'name': '肖申克的救赎', 'star': '主演:蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿', 'time': '1994-09-10'}
{'name': '美丽人生', 'star': '主演:罗伯托·贝尼尼,尼可莱塔·布拉斯基,乔治·坎塔里尼', 'time': '2020-01-03'}
{'name': '倩女幽魂', 'star': '主演:张国荣,王祖贤,午马', 'time': '2011-04-30'}
{'name': '搏击俱乐部', 'star': '主演:爱德华·哈里森·诺顿,布拉德·皮特,海伦娜·伯翰·卡特', 'time': '1999-09-10'}
{'name': '春光乍泄', 'star': '主演:张国荣,梁朝伟,张震', 'time': '1997-05-17'}
{'name': '海上钢琴师', 'star': '主演:蒂姆·罗斯,比尔·努恩,克兰伦斯·威廉姆斯三世', 'time': '2019-11-15'}
{'name': '新龙门客栈', 'star': '主演:张曼玉,梁家辉,甄子丹', 'time': '2012-02-24'}
{'name': '驯龙高手', 'star': '主演:杰伊·巴鲁切尔,杰拉德·巴特勒,亚美莉卡·费雷拉', 'time': '2010-05-14'}
{'name': '教父2', 'star': '主演:阿尔·帕西诺,罗伯特·德尼罗,黛安·基顿', 'time': '1974-12-12'}
{'name': '美国往事', 'star': '主演:罗伯特·德尼罗,詹姆斯·伍兹,伊丽莎白·麦戈文', 'time': '2015-04-23'}
{'name': '魂断蓝桥', 'star': '主演:费雯·丽,罗伯特·泰勒,露塞尔·沃特森', 'time': '1940-05-17'}
{'name': '狮子王', 'star': '主演:马修·布罗德里克,尼基塔·卡兰姆,詹姆斯·厄尔·琼斯', 'time': '1995-07-15'}
{'name': '疯狂原始人', 'star': '主演:尼古拉斯·凯奇,艾玛·斯通,瑞安·雷诺兹', 'time': '2013-04-20'}
{'name': '唐伯虎点秋香', 'star': '主演:周星驰,巩俐,郑佩佩', 'time': '1993-07-01'}
{'name': '速度与激情5', 'star': '主演:范·迪塞尔,保罗·沃克,道恩·强森', 'time': '2011-05-12'}
{'name': 'V字仇杀队', 'star': '主演:娜塔莉·波特曼,雨果·维文,斯蒂芬·瑞', 'time': '2005-12-11'}
{'name': '龙猫', 'star': '主演:秦岚,糸井重里,岛本须美', 'time': '2018-12-14'}
{'name': '本杰明·巴顿奇事', 'star': '主演:布拉德·皮特,凯特·布兰切特,塔拉吉·P·汉森', 'time': '2008-12-25'}
{'name': '指环王2:双塔奇兵', 'star': '主演:伊莱贾·伍德,伊恩·麦克莱恩,丽芙·泰勒', 'time': '2003-04-25'}
{'name': '指环王1:护戒使者', 'star': '主演:伊莱贾·伍德,伊恩·麦克莱恩,丽芙·泰勒', 'time': '2002-04-04'}
{'name': '时空恋旅人', 'star': '主演:瑞秋·麦克亚当斯,多姆纳尔·格里森,比尔·奈伊', 'time': '2013-09-04'}
{'name': '末代皇帝', 'star': '主演:尊龙,陈冲,彼得·奥图尔', 'time': '1987-10-23'}
{'name': '天空之城', 'star': '主演:寺田农,鹫尾真知子,龟山助清', 'time': '1992-05-01'}
{'name': '风之谷', 'star': '主演:岛本须美,永井一郎,坂本千夏', 'time': '1992-05'}
{'name': '幽灵公主', 'star': '主演:松田洋治,石田百合子,田中裕子', 'time': '1998-05-01'}
{'name': '蝙蝠侠:黑暗骑士崛起', 'star': '主演:克里斯蒂安·贝尔,迈克尔·凯恩,加里·奥德曼', 'time': '2012-08-27'}
{'name': '十二怒汉', 'star': '主演:亨利·方达,李·科布,马丁·鲍尔萨姆', 'time': '1957-04-13'}
{'name': '素媛', 'star': '主演:李来,薛耿求,严志媛', 'time': '2013-10-02'}
{'name': '大话西游之大圣娶亲', 'star': '主演:周星驰,朱茵,莫文蔚', 'time': '2014-10-24'}
{'name': '教父', 'star': '主演:马龙·白兰度,阿尔·帕西诺,詹姆斯·肯恩', 'time': '2015-04-18'}
{'name': '海洋', 'star': '主演:雅克·贝汉,姜文,兰斯洛特·佩林', 'time': '2011-08-12'}
{'name': '黑客帝国', 'star': '主演:基努·里维斯,凯瑞-安·莫斯,劳伦斯·菲什伯恩', 'time': '2000-01-14'}
{'name': '鬼子来了', 'star': '主演:姜文,姜宏波,陈强', 'time': '2000-05-13'}
{'name': '哈利·波特与死亡圣器(下)', 'star': '主演:丹尼尔·雷德克里夫,鲁伯特·格林特,艾玛·沃特森', 'time': '2011-08-04'}
{'name': '辛德勒的名单', 'star': '主演:连姆·尼森,拉尔夫·费因斯,本·金斯利', 'time': '1993-11-30'}
{'name': '指环王3:王者无敌', 'star': '主演:伊莱贾·伍德,伊恩·麦克莱恩,丽芙·泰勒', 'time': '2004-03-15'}
{'name': '7号房的礼物', 'star': '主演:柳承龙,郑镇荣,朴信惠', 'time': '2013-01-23'}
{'name': '盗梦空间', 'star': '主演:莱昂纳多·迪卡普里奥,渡边谦,约瑟夫·高登-莱维特', 'time': '2010-09-01'}
{'name': '加勒比海盗', 'star': '主演:约翰尼·德普,凯拉·奈特莉,奥兰多·布鲁姆', 'time': '2003-11-21'}
{'name': '当幸福来敲门', 'star': '主演:威尔·史密斯,贾登·史密斯,坦迪·牛顿', 'time': '2008-01-17'}
{'name': '穿条纹睡衣的男孩', 'star': '主演:阿沙·巴特菲尔德,维拉·法梅加,大卫·休里斯', 'time': '2008-08-28'}
{'name': '音乐之声', 'star': '主演:朱莉·安德鲁斯,克里斯托弗·普卢默,埃琳诺·帕克', 'time': '1965-03-02'}
{'name': '无间道', 'star': '主演:刘德华,梁朝伟,黄秋生', 'time': '2003-09-05'}
{'name': '致命魔术', 'star': '主演:休·杰克曼,克里斯蒂安·贝尔,迈克尔·凯恩', 'time': '2006-10-17'}
{'name': '小鞋子', 'star': '主演:默罕默德·阿米尔·纳吉,Kamal Mirkarimi,Behzad Rafi', 'time': '1997(伊朗)'}
{'name': '萤火之森', 'star': '主演:内山昂辉,佐仓绫音,后藤弘树', 'time': '2011-09-17'}
{'name': '少年派的奇幻漂流', 'star': '主演:苏拉·沙玛,伊尔凡·可汗,塔布', 'time': '2012-11-22'}
{'name': '断背山', 'star': '主演:希斯·莱杰,杰克·吉伦哈尔,米歇尔·威廉姆斯', 'time': '2005-09-02'}
{'name': '罗马假日', 'star': '主演:格利高里·派克,奥黛丽·赫本,埃迪·艾伯特', 'time': '1953-08-20'}
{'name': '夜访吸血鬼', 'star': '主演:汤姆·克鲁斯,布拉德·皮特,克尔斯滕·邓斯特', 'time': '1994-11-11'}
{'name': '天堂电影院', 'star': '主演:菲利浦·诺瓦雷,赛尔乔·卡斯特利托,蒂兹亚娜·罗达托', 'time': '1988-11-17'}
{'name': '怦然心动', 'star': '主演:玛德琳·卡罗尔,卡兰·麦克奥利菲,艾丹·奎因', 'time': '2010-07-26'}
{'name': '乱世佳人', 'star': '主演:费雯·丽,克拉克·盖博,奥利维娅·德哈维兰', 'time': '1939-12-15'}
{'name': '完美的世界', 'star': '主演:凯文·科斯特纳,克林特·伊斯特伍德,T·J·劳瑟', 'time': '1993-11-24'}
{'name': '霸王别姬', 'star': '主演:张国荣,张丰毅,巩俐', 'time': '1993-07-26'}
{'name': '七武士', 'star': '主演:三船敏郎,志村乔,千秋实', 'time': '1954-04-26'}
{'name': '忠犬八公的故事', 'star': '主演:Forest,理查·基尔,琼·艾伦', 'time': '2009-06-13'}
{'name': '海豚湾', 'star': '主演:里克·奥巴瑞,路易·西霍尤斯,哈迪·琼斯', 'time': '2009-07-31'}
{'name': '拯救大兵瑞恩', 'star': '主演:汤姆·汉克斯,马特·达蒙,汤姆·塞兹摩尔', 'time': '1998-11-13'}
{'name': '机器人总动员', 'star': '主演:本·贝尔特,艾丽莎·奈特,杰夫·格尔林', 'time': '2008-06-27'}
{'name': '神偷奶爸', 'star': '主演:史蒂夫·卡瑞尔,杰森·席格尔,拉塞尔·布兰德', 'time': '2010-06-20'}
{'name': '放牛班的春天', 'star': '主演:热拉尔·朱尼奥,让-巴蒂斯特·莫尼耶,玛丽·布奈尔', 'time': '2004-10-16'}
{'name': '熔炉', 'star': '主演:孔刘,郑有美,金智英', 'time': '2011-09-22'}
{'name': '阿凡达', 'star': '主演:萨姆·沃辛顿,佐伊·索尔达娜,米歇尔·罗德里格兹', 'time': '2010-01-04'}
{'name': '千与千寻', 'star': '主演:柊瑠美,周冬雨,入野自由', 'time': '2019-06-21'}
{'name': '无敌破坏王', 'star': '主演:约翰·C·赖利,萨拉·西尔弗曼,简·林奇', 'time': '2012-11-06'}
爬取数量:100
程序结束!
爬虫数据解析模块——xpath
定义
XPath即为XML路径语言,它是一种用来确定XML文档中某部分位置的语言,同样适用于HTML文档的检索
语法
一个示例说明基础语法:
测试HTML代码如下:
<ul class="CarList">
<li class="bjd" id="car_001" href="http://www.bjd.com/">
<p class="name">布加迪</p>
<p class="model">威航</p>
<p class="price">2500万</p>
<p class="color">红色</p>
</li>
<li class="byd" id="car_002" href="http://www.byd.com/">
<p class="name">比亚迪</p>
<p class="model">秦</p>
<p class="price">15万</p>
<p class="color">白色</p>
</li>
</ul>
匹配演示:
1、查找所有的li节点
//li
2、获取所有汽车的名称: 所有li节点下的子节点p的值 (class属性值为name)
//li/p[@class="name"]
3、找比亚迪车的信息: 获取ul节点下第2个li节点的汽车信息
//ul/li[2]
4、获取所有汽车的链接: ul节点下所有li子节点的href属性的值
//ul/li/@href
# 只要涉及到条件,加 []
# 只要获取属性值,加 @
选取节点:
1、// :从所有节点中查找(包括子节点和后代节点)
2、@ :获取属性值
# 使用场景1(属性值作为条件)
//div[@class="movie-item-info"]
# 使用场景2(直接获取属性值)
//div[@class="movie-item-info"]/a/img/@src
匹配多路径
xpath表达式1 | xpath表达式2 | xpath表达式3
常用函数
1、contains() :匹配属性值中包含某些字符串节点
# 查找id属性值中包含字符串 "car_" 的 li 节点
//li[contains(@id,"car_")]
2、text() :获取节点的文本内容
# 查找所有汽车的价格
//li/p[@class="price"]/text()
lxml解析库
安装
sudo pip3 install lxml
使用流程
1、导模块
from lxml import etree
2、创建解析对象
parse_html = etree.HTML(html)
3、解析对象调用xpath
r_list = parse_html.xpath('xpath表达式')
html样本
<div class="wrapper">
<a href="/" id="channel">新浪社会</a>
<ul id="nav">
<li><a href="http://domestic.sina.com/" title="国内">国内</a></li>
<li><a href="http://world.sina.com/" title="国际">国际</a></li>
<li><a href="http://mil.sina.com/" title="军事">军事</a></li>
<li><a href="http://photo.sina.com/" title="图片">图片</a></li>
<li><a href="http://society.sina.com/" title="社会">社会</a></li>
<li><a href="http://ent.sina.com/" title="娱乐">娱乐</a></li>
<li><a href="http://tech.sina.com/" title="科技">科技</a></li>
<li><a href="http://sports.sina.com/" title="体育">体育</a></li>
<li><a href="http://finance.sina.com/" title="财经">财经</a></li>
<li><a href="http://auto.sina.com/" title="汽车">汽车</a></li>
</ul>
</div>
示例+练习
from lxml import etree
html = '''
<div class="wrapper">
<a href="/" id="channel">新浪社会</a>
<ul id="nav">
<li><a href="http://domestic.sina.com/" title="国内">国内</a></li>
<li><a href="http://world.sina.com/" title="国际">国际</a></li>
<li><a href="http://mil.sina.com/" title="军事">军事</a></li>
<li><a href="http://photo.sina.com/" title="图片">图片</a></li>
<li><a href="http://society.sina.com/" title="社会">社会</a></li>
<li><a href="http://ent.sina.com/" title="娱乐">娱乐</a></li>
<li><a href="http://tech.sina.com/" title="科技">科技</a></li>
<li><a href="http://sports.sina.com/" title="体育">体育</a></li>
<li><a href="http://finance.sina.com/" title="财经">财经</a></li>
<li><a href="http://auto.sina.com/" title="汽车">汽车</a></li>
</ul>
</div>'''
# 创建解析对象
parse_html = etree.HTML(html)
# 调用xpath返回结束,text()为文本内容
a_list = parse_html.xpath('//a/text()')
print(a_list)
# 提取所有的href的属性值
href_list = parse_html.xpath('//a/@href')
print(href)
# 提取所有href的值,不包括 /
href_list = parse_html.xpath('//ul[@id="nav"]/li/a/@href')
print(href_list)
# 获取 图片、军事、...,不包括新浪社会
a_list = parse_html.xpath('//ul[@id="nav"]/li/a/text()')
for a in a_list:
print(a)
xpath最常使用方法
1、先匹配节点对象列表
# r_list: ['节点对象1','节点对象2']
r_list = parse_html.xpath('基准xpath表达式')
2、遍历每个节点对象,利用节点对象继续调用 xpath
for r in r_list:
name = r.xpath('./xxxxxx')
star = r.xpath('.//xxxxx')
time = r.xpath('.//xxxxx')
案例:猫眼电影数据抓取
参见代码:Spider_Codes/demo04_MaoYanMovie_xpath_OOP.py
案例:链接二手房爬取房源信息
参见代码:Spider_Codes/demo05_LianjiaHouseSpider_OOP.py
案例:百度贴吧图片爬取
参见代码:Spider_Codes/demo06_BaiduTiebaSpider_OOP.py
案例:电影天堂二级页面抓取电影磁力下载链接
参见代码:Spider_Codes/demo07_MoiveDYTT.py
爬虫数据解析模块——BeautifulSoup4
Bs4基本介绍及用法
基本介绍
BeautifulSoup4,简称bs4,是一个可以从HTML或XML文档中提取数据的Python库.实现对HTML或XML文档解析功能的库有很多,前文我们已经学习使用了很多库,比如最最基本的re正则表达式,它是最基本的HTML或XML文档解析库,特点就是依托正则表达式语法,灵活且高效;还有xpath解析,依托DOM(document object model,文档对象模型)节点对象的解析库,功能也是非常强大。但这两个常见的基本解析库,其具有一个共同的特点:具有其独特的解析语法,两者无一不需要先去学习其复杂的解析语法,再去学习使用解析库解析HTML文档。而bs4的优势就在于没有固定繁杂的解析语法,一切均依托内置的转换器实现功能,简单易上手,同时大幅提升效率,对新手小白极其友好。
BeautifulSoup4的下载及安装
无论是在windows环境下还是Linux、Unix(mac)下,下载安装的方式都是统一的,即都通过pip包管理工具进行安装。安装命令如下(需要先安装pip包管理工具,不会安装的前文已经说到,自行阅读操作安装一下):
pip install beautifulsoup4 -i https://pypi.douban.com/simple
BeautifulSoup4模块导入
form bs4 import BeautifulSoup
bs4解析库
BeautifulSoup默认支持Python的标准HTML解析库,但是它也支持一些第三方的解析库:
| 序号 | 解析库 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|---|
| 1 | Python标准库 | BeautifulSoup(html,’html.parser’) | Python内置标准库;执行速度快 | 容错能力较差 |
| 2 | lxml HTML解析库 | BeautifulSoup(html,’lxml’) | 速度快;容错能力强 | 需要安装,需要C语言库 |
| 3 | lxml XML解析库 | BeautifulSoup(html,[‘lxml’,’xml’]) | 速度快;容错能力强;支持XML格式 | 需要C语言库 |
| 4 | htm5lib解析库 | BeautifulSoup(html,’htm5llib’) | 以浏览器方式解析,最好的容错性 | 速度慢 |
解析器安装
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml .根据操作系统不同,可以选择下列方法来安装lxml:
apt-get install Python-lxml
easy_install lxml
pip install lxml
另一个可供选择的解析器是纯Python实现的 html5lib , html5lib的解析方式与浏览器相同,可以选择下列方法来安装html5lib:
apt-get install Python-html5lib
easy_install html5lib
pip install html5lib
推荐使用lxml作为解析器,因为效率更高. 在Python2.7.3之前的版本和Python3中3.2.2之前的版本,必须安装lxml或html5lib, 因为那些Python版本的标准库中内置的HTML解析方法不够稳定.
提示: 如果一段HTML或XML文档格式不正确的话,那么在不同的解析器中返回的结果可能是不一样的.
基本用法
#导包
from bs4 import BeautifulSoup
#文档对象 = BeautifulSoup(str[doc],[parserMethod])
soup = BeautifulSoup(open("index.html"),'html.parser')#传入文件句柄
soup = BeautifulSoup("<html>data</html>",'lxml')#传入字符串
bs4对象种类——4大常用对象
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
- Tag
- NavigableString
- BeautifulSoup
- Comment
Tag对象
Tag对象与XML或HTML原生文档中的tag相同:
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>')
tag = soup.b
type(tag)
# <class 'bs4.element.Tag'>
Tag有很多方法和属性,其中最重要的属性是: name和attributes
name属性
每个tag都有自己的名字,通过.name获取:
tag.name
# u'b'
如果改变了tag的name,那将影响所有通过当前Beautiful Soup对象生成的HTML文档:
tag.name = "blockquote"
tag
# <blockquote class="boldest">Extremely bold</blockquote>
attributes属性
一个tag可能有很多个属性. tag <b class="boldest">有一个 “class” 的属性,值为 “boldest” . tag的属性的操作方法与字典相同:
tag['class']
# u'boldest'
也可以直接”点”取属性, 比如: .attrs :
tag.attrs
# {u'class': u'boldest'}
tag的属性可以被添加,删除或修改. 再说一次, tag的属性操作方法与字典一样:
tag['class'] = 'verybold'
tag['id'] = 1
tag
# <blockquote class="verybold" id="1">Extremely bold</blockquote>
del tag['class']
del tag['id']
tag
# <blockquote>Extremely bold</blockquote>
tag['class']
# KeyError: 'class'
print(tag.get('class'))
# None
多值属性
HTML 4定义了一系列可以包含多个值的属性.在HTML5中移除了一些,却增加更多.最常见的多值的属性是 class (一个tag可以有多个CSS的class). 还有一些属性 rel , rev , accept-charset , headers , accesskey . 在Beautiful Soup中多值属性的返回类型是list:
css_soup = BeautifulSoup('<p class="body strikeout"></p>')
css_soup.p['class']
# ["body", "strikeout"]
css_soup = BeautifulSoup('<p class="body"></p>')
css_soup.p['class']
# ["body"]
如果某个属性看起来好像有多个值,但在任何版本的HTML定义中都没有被定义为多值属性,那么Beautiful Soup会将这个属性作为字符串返回:
id_soup = BeautifulSoup('<p id="my id"></p>')
id_soup.p['id']
# 'my id'
将tag转换成字符串时,多值属性会合并为一个值:
rel_soup = BeautifulSoup('<p>Back to the <a rel="index">homepage</a></p>')
rel_soup.a['rel']
# ['index']
rel_soup.a['rel'] = ['index', 'contents']
print(rel_soup.p)
# <p>Back to the <a rel="index contents">homepage</a></p>
如果转换的文档是XML格式,那么tag中不包含多值属性:
xml_soup = BeautifulSoup('<p class="body strikeout"></p>', 'xml')
xml_soup.p['class']
# u'body strikeout'
NavigableString对象(可遍历字符串)
字符串常被包含在tag内.Beautiful Soup用 NavigableString 类来包装tag中的字符串:
tag.string
# u'Extremely bold'
type(tag.string)
# <class 'bs4.element.NavigableString'>
一个 NavigableString 字符串与Python中的Unicode字符串相同,并且还支持包含在 遍历文档树 和 搜索文档树 中的一些特性. 通过 unicode() 方法可以直接将 NavigableString 对象转换成Unicode字符串:
unicode_string = unicode(tag.string)
unicode_string
# u'Extremely bold'
type(unicode_string)
# <type 'unicode'>
tag中包含的字符串不能编辑,但是可以被替换成其它的字符串,用 replace_with() 方法:
tag.string.replace_with("No longer bold")
tag
# <blockquote>No longer bold</blockquote>
NavigableString 对象支持 遍历文档树 和 搜索文档树 中定义的大部分属性, 并非全部.尤其是,一个字符串不能包含其它内容(tag能够包含字符串或是其它tag),字符串不支持 .contents 或 .string 属性或 find() 方法.
如果想在Beautiful Soup之外使用 NavigableString 对象,需要调用 unicode() 方法,将该对象转换成普通的Unicode字符串,否则就算Beautiful Soup已方法已经执行结束,该对象的输出也会带有对象的引用地址.这样会浪费内存.
BeautifulSoup对象
BeautifulSoup 对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象,它支持 遍历文档树 和 搜索文档树 中描述的大部分的方法.
因为 BeautifulSoup 对象并不是真正的HTML或XML的tag,所以它没有name和attribute属性.但有时查看它的 .name 属性是很方便的,所以 BeautifulSoup 对象包含了一个值为 “[document]” 的特殊属性 .name
soup.name
# u'[document]'
Comment对象(文档注释)
Tag , NavigableString , BeautifulSoup 几乎覆盖了html和xml中的所有内容,但是还有一些特殊对象.容易让人担心的内容是文档的注释部分:
markup = "<b><!--Hey, buddy. Want to buy a used parser?--></b>"
soup = BeautifulSoup(markup)
comment = soup.b.string
type(comment)
# <class 'bs4.element.Comment'>
Comment 对象是一个特殊类型的 NavigableString 对象:
comment
# u'Hey, buddy. Want to buy a used parser'
但是当它出现在HTML文档中时, Comment 对象会使用特殊的格式输出:
print(soup.b.prettify())
# <b>
# <!--Hey, buddy. Want to buy a used parser?-->
# </b>
Beautiful Soup中定义的其它类型都可能会出现在XML的文档中: CData , ProcessingInstruction , Declaration , Doctype .与 Comment 对象类似,这些类都是 NavigableString 的子类,只是添加了一些额外的方法的字符串独享.下面是用CDATA来替代注释的例子:
from bs4 import CData
cdata = CData("A CDATA block")
comment.replace_with(cdata)
print(soup.b.prettify())
# <b>
# <![CDATA[A CDATA block]]>
# </b>
遍历文档树
还拿”爱丽丝梦游仙境”的文档来做例子:
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'html.parser')
通过这段例子来演示怎样从文档的一段内容找到另一段内容
子节点
一个Tag可能包含多个字符串或其它的Tag,这些都是这个Tag的子节点.Beautiful Soup提供了许多操作和遍历子节点的属性.
注意: Beautiful Soup中字符串节点不支持这些属性,因为字符串没有子节点
tag的名字
操作文档树最简单的方法就是告诉它你想获取的tag的name.如果想获取 <head> 标签,只要用 soup.head :
soup.head
# <head><title>The Dormouse's story</title></head>
soup.title
# <title>The Dormouse's story</title>
这是个获取tag的小窍门,可以在文档树的tag中多次调用这个方法.下面的代码可以获取<body>标签中的第一个标签:
soup.body.b
# <b>The Dormouse's story</b>
通过点取属性的方式只能获得当前名字的第一个tag:
soup.a
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
如果想要得到所有的标签,或是通过名字得到比一个tag更多的内容的时候,就需要用到 Searching the tree 中描述的方法,比如: find_all()
soup.find_all('a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
.contents 和 .children
tag的 .contents 属性可以将tag的子节点以列表的方式输出:
head_tag = soup.head
head_tag
# <head><title>The Dormouse's story</title></head>
head_tag.contents
[<title>The Dormouse's story</title>]
title_tag = head_tag.contents[0]
title_tag
# <title>The Dormouse's story</title>
title_tag.contents
# [u'The Dormouse's story']
BeautifulSoup 对象本身一定会包含子节点,也就是说<html>标签也是 BeautifulSoup 对象的子节点:
len(soup.contents)
# 1
soup.contents[0].name
# u'html'
字符串没有 .contents 属性,因为字符串没有子节点:
text = title_tag.contents[0]
text.contents
# AttributeError: 'NavigableString' object has no attribute 'contents'
通过tag的 .children 生成器,可以对tag的子节点进行循环:
for child in title_tag.children:
print(child)
# The Dormouse's story
.descendants
.contents 和 .children 属性仅包含tag的直接子节点.例如,<head>标签只有一个直接子节点
head_tag.contents
# [<title>The Dormouse's story</title>]
但是
for child in head_tag.descendants:
print(child)
# <title>The Dormouse's story</title>
# The Dormouse's story
上面的例子中, <head>标签只有一个子节点,但是有2个子孙节点:<head>节点和<head>的子节点, BeautifulSoup 有一个直接子节点(<html>节点),却有很多子孙节点:
len(list(soup.children))
# 1
len(list(soup.descendants))
# 25
.string
如果tag只有一个 NavigableString 类型子节点,那么这个tag可以使用 .string 得到子节点:
title_tag.string
# u'The Dormouse's story'
如果一个tag仅有一个子节点,那么这个tag也可以使用 .string 方法,输出结果与当前唯一子节点的 .string 结果相同:
head_tag.contents
# [<title>The Dormouse's story</title>]
head_tag.string
# u'The Dormouse's story'
如果tag包含了多个子节点,tag就无法确定 .string 方法应该调用哪个子节点的内容, .string 的输出结果是 None :
print(soup.html.string)
# None
.strings 和 stripped_strings
如果tag中包含多个字符串 [2] ,可以使用 .strings 来循环获取:
for string in soup.strings:
print(repr(string))
# u"The Dormouse's story"
# u'\n\n'
# u"The Dormouse's story"
# u'\n\n'
# u'Once upon a time there were three little sisters; and their names were\n'
# u'Elsie'
# u',\n'
# u'Lacie'
# u' and\n'
# u'Tillie'
# u';\nand they lived at the bottom of a well.'
# u'\n\n'
# u'...'
# u'\n'
输出的字符串中可能包含了很多空格或空行,使用 .stripped_strings 可以去除多余空白内容:
for string in soup.stripped_strings:
print(repr(string))
# u"The Dormouse's story"
# u"The Dormouse's story"
# u'Once upon a time there were three little sisters; and their names were'
# u'Elsie'
# u','
# u'Lacie'
# u'and'
# u'Tillie'
# u';\nand they lived at the bottom of a well.'
# u'...'
全部是空格的行会被忽略掉,段首和段末的空白会被删除
父节点
继续分析文档树,每个tag或字符串都有父节点:被包含在某个tag中
.parent
通过 .parent 属性来获取某个元素的父节点.在例子“爱丽丝”的文档中,<head>标签是
title_tag = soup.title
title_tag
# <title>The Dormouse's story</title>
title_tag.parent
# <head><title>The Dormouse's story</title></head>
文档title的字符串也有父节点:
title_tag.string.parent
# <title>The Dormouse's story</title>
文档的顶层节点比如<html>的父节点是 BeautifulSoup 对象:
html_tag = soup.html
type(html_tag.parent)
# <class 'bs4.BeautifulSoup'>
BeautifulSoup 对象的 .parent 是None:
print(soup.parent)
# None
.parents
通过元素的 .parents 属性可以递归得到元素的所有父辈节点,下面的例子使用了 .parents 方法遍历了标签到根节点的所有节点.
link = soup.a
link
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
for parent in link.parents:
if parent is None:
print(parent)
else:
print(parent.name)
# p
# body
# html
# [document]
# None
兄弟节点
看一段简单的例子:
sibling_soup = BeautifulSoup("<a><b>text1</b><c>text2</c></b></a>")
print(sibling_soup.prettify())
# <html>
# <body>
# <a>
# <b>
# text1
# </b>
# <c>
# text2
# </c>
# </a>
# </body>
# </html>
因为标签和
.next_sibling 和 .previous_sibling
在文档树中,使用 .next_sibling 和 .previous_sibling 属性来查询兄弟节点:
sibling_soup.b.next_sibling
# <c>text2</c>
sibling_soup.c.previous_sibling
# <b>text1</b>
标签有 .next_sibling 属性,但是没有 .previous_sibling 属性,因为标签在同级节点中是第一个.同理,
print(sibling_soup.b.previous_sibling)
# None
print(sibling_soup.c.next_sibling)
# None
例子中的字符串“text1”和“text2”不是兄弟节点,因为它们的父节点不同:
sibling_soup.b.string
# u'text1'
print(sibling_soup.b.string.next_sibling)
# None
实际文档中的tag的 .next_sibling 和 .previous_sibling 属性通常是字符串或空白. 看看“爱丽丝”文档:
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
如果以为第一个标签的 .next_sibling 结果是第二个标签,那就错了,真实结果是第一个标签和第二个标签之间的顿号和换行符:
link = soup.a
link
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
link.next_sibling
# u',\n'
link.next_sibling.next_sibling
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
.next_siblings 和 .previous_siblings
通过 .next_siblings 和 .previous_siblings 属性可以对当前节点的兄弟节点迭代输出:
for sibling in soup.a.next_siblings:
print(repr(sibling))
# u',\n'
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
# u' and\n'
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
# u'; and they lived at the bottom of a well.'
# None
for sibling in soup.find(id="link3").previous_siblings:
print(repr(sibling))
# ' and\n'
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
# u',\n'
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
# u'Once upon a time there were three little sisters; and their names were\n'
# None
回退和前进
看一下“爱丽丝” 文档:
<html><head><title>The Dormouse's story</title></head>
<p class="title"><b>The Dormouse's story</b></p>
HTML解析器把这段字符串转换成一连串的事件: “打开<html>标签”,”打开一个<head>标签”,”打开一个
.next_element 和 .previous_element
.next_element 属性指向解析过程中下一个被解析的对象(字符串或tag),结果可能与 .next_sibling 相同,但通常是不一样的.
这是“爱丽丝”文档中最后一个标签,它的 .next_sibling 结果是一个字符串,因为当前的解析过程 [2] 因为当前的解析过程因为遇到了标签而中断了:
last_a_tag = soup.find("a", id="link3")
last_a_tag
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
last_a_tag.next_sibling
# '; and they lived at the bottom of a well.'
但这个标签的 .next_element 属性结果是在标签被解析之后的解析内容,不是标签后的句子部分,应该是字符串”Tillie”:
last_a_tag.next_element
# u'Tillie'
这是因为在原始文档中,字符串“Tillie” 在分号前出现,解析器先进入标签,然后是字符串“Tillie”,然后关闭标签,然后是分号和剩余部分.分号与标签在同一层级,但是字符串“Tillie”会被先解析.
.previous_element 属性刚好与 .next_element 相反,它指向当前被解析的对象的前一个解析对象:
last_a_tag.previous_element
# u' and\n'
last_a_tag.previous_element.next_element
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
.next_elements 和 .previous_elements
通过 .next_elements 和 .previous_elements 的迭代器就可以向前或向后访问文档的解析内容,就好像文档正在被解析一样:
for element in last_a_tag.next_elements:
print(repr(element))
# u'Tillie'
# u';\nand they lived at the bottom of a well.'
# u'\n\n'
# <p class="story">...</p>
# u'...'
# u'\n'
# None
搜索文档树
Beautiful Soup定义了很多搜索方法,这里着重介绍2个: find() 和 find_all() .其它方法的参数和用法类似,请读者举一反三.
再以“爱丽丝”文档作为例子:
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'html.parser')
使用 find_all() 类似的方法可以查找到想要查找的文档内容.
过滤器
介绍 find_all() 方法前,先介绍一下过滤器的类型 [3] ,这些过滤器贯穿整个搜索的API.过滤器可以被用在tag的name中,节点的属性中,字符串中或他们的混合中.
字符串
最简单的过滤器是字符串.在搜索方法中传入一个字符串参数,Beautiful Soup会查找与字符串完整匹配的内容,下面的例子用于查找文档中所有的标签:
soup.find_all('b')
# [<b>The Dormouse's story</b>]
如果传入字节码参数,Beautiful Soup会当作UTF-8编码,可以传入一段Unicode 编码来避免Beautiful Soup解析编码出错
正则表达式
如果传入正则表达式作为参数,Beautiful Soup会通过正则表达式的 match() 来匹配内容.下面例子中找出所有以b开头的标签,这表示<body>和标签都应该被找到:
import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
# body
# b
下面代码找出所有名字中包含”t”的标签:
for tag in soup.find_all(re.compile("t")):
print(tag.name)
# html
# title
列表
如果传入列表参数,Beautiful Soup会将与列表中任一元素匹配的内容返回.下面代码找到文档中所有标签和标签:
soup.find_all(["a", "b"])
# [<b>The Dormouse's story</b>,
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
True
True 可以匹配任何值,下面代码查找到所有的tag,但是不会返回字符串节点
for tag in soup.find_all(True):
print(tag.name)
# html
# head
# title
# body
# p
# b
# p
# a
# a
# a
# p
方法
如果没有合适过滤器,那么还可以定义一个方法,方法只接受一个元素参数 [4] ,如果这个方法返回 True 表示当前元素匹配并且被找到,如果不是则反回 False
下面方法校验了当前元素,如果包含 class 属性却不包含 id 属性,那么将返回 True:
def has_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id')
将这个方法作为参数传入 find_all() 方法,将得到所有<p>标签:
soup.find_all(has_class_but_no_id)
# [<p class="title"><b>The Dormouse's story</b></p>,
# <p class="story">Once upon a time there were...</p>,
# <p class="story">...</p>]
返回结果中只有<p>标签没有标签,因为标签还定义了”id”,没有返回<html>和<head>,因为<html>和<head>中没有定义”class”属性.
通过一个方法来过滤一类标签属性的时候, 这个方法的参数是要被过滤的属性的值, 而不是这个标签. 下面的例子是找出 href 属性不符合指定正则的 a 标签.
def not_lacie(href):
return href and not re.compile("lacie").search(href)
soup.find_all(href=not_lacie)
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
标签过滤方法可以使用复杂方法. 下面的例子可以过滤出前后都有文字的标签.
from bs4 import NavigableString
def surrounded_by_strings(tag):
return (isinstance(tag.next_element, NavigableString)
and isinstance(tag.previous_element, NavigableString))
for tag in soup.find_all(surrounded_by_strings):
print tag.name
# p
# a
# a
# a
# p
现在来了解一下搜索方法的细节.
find_all()
find_all( name , attrs , recursive , string , **kwargs )
find_all() 方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件.这里有几个例子:
soup.find_all("title")
# [<title>The Dormouse's story</title>]
soup.find_all("p", "title")
# [<p class="title"><b>The Dormouse's story</b></p>]
soup.find_all("a")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.find_all(id="link2")
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
import re
soup.find(string=re.compile("sisters"))
# u'Once upon a time there were three little sisters; and their names were\n'
有几个方法很相似,还有几个方法是新的,参数中的 string 和 id 是什么含义? 为什么 find_all("p", "title") 返回的是CSS Class为”title”的<p>标签? 我们来仔细看一下 find_all() 的参数
name 参数
name 参数可以查找所有名字为 name 的tag,字符串对象会被自动忽略掉.
简单的用法如下:
soup.find_all("title")
# [<title>The Dormouse's story</title>]
重申: 搜索 name 参数的值可以使任一类型的 过滤器 ,字符窜,正则表达式,列表,方法或是 True .
keyword 参数
如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作指定名字tag的属性来搜索,如果包含一个名字为 id 的参数,Beautiful Soup会搜索每个tag的”id”属性.
soup.find_all(id='link2')
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
如果传入 href 参数,Beautiful Soup会搜索每个tag的”href”属性:
soup.find_all(href=re.compile("elsie"))
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
搜索指定名字的属性时可以使用的参数值包括 字符串 , 正则表达式 , 列表, True .
下面的例子在文档树中查找所有包含 id 属性的tag,无论 id 的值是什么:
soup.find_all(id=True)
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
使用多个指定名字的参数可以同时过滤tag的多个属性:
soup.find_all(href=re.compile("elsie"), id='link1')
# [<a class="sister" href="http://example.com/elsie" id="link1">three</a>]
有些tag属性在搜索不能使用,比如HTML5中的 data-* 属性:
data_soup = BeautifulSoup('<div data-foo="value">foo!</div>')
data_soup.find_all(data-foo="value")
# SyntaxError: keyword can't be an expression
但是可以通过 find_all() 方法的 attrs 参数定义一个字典参数来搜索包含特殊属性的tag:
data_soup.find_all(attrs={"data-foo": "value"})
# [<div data-foo="value">foo!</div>]
按CSS搜索
按照CSS类名搜索tag的功能非常实用,但标识CSS类名的关键字 class 在Python中是保留字,使用 class 做参数会导致语法错误.从Beautiful Soup的4.1.1版本开始,可以通过 class_ 参数搜索有指定CSS类名的tag:
soup.find_all("a", class_="sister")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
class_ 参数同样接受不同类型的 过滤器 ,字符串,正则表达式,方法或 True :
soup.find_all(class_=re.compile("itl"))
# [<p class="title"><b>The Dormouse's story</b></p>]
def has_six_characters(css_class):
return css_class is not None and len(css_class) == 6
soup.find_all(class_=has_six_characters)
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
tag的 class 属性是 多值属性 .按照CSS类名搜索tag时,可以分别搜索tag中的每个CSS类名:
css_soup = BeautifulSoup('<p class="body strikeout"></p>')
css_soup.find_all("p", class_="strikeout")
# [<p class="body strikeout"></p>]
css_soup.find_all("p", class_="body")
# [<p class="body strikeout"></p>]
搜索 class 属性时也可以通过CSS值完全匹配:
css_soup.find_all("p", class_="body strikeout")
# [<p class="body strikeout"></p>]
完全匹配 class 的值时,如果CSS类名的顺序与实际不符,将搜索不到结果:
soup.find_all("a", attrs={"class": "sister"})
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
string 参数
通过 string 参数可以搜搜文档中的字符串内容.与 name 参数的可选值一样, string 参数接受 字符串 , 正则表达式 , 列表, True . 看例子:
soup.find_all(string="Elsie")
# [u'Elsie']
soup.find_all(string=["Tillie", "Elsie", "Lacie"])
# [u'Elsie', u'Lacie', u'Tillie']
soup.find_all(string=re.compile("Dormouse"))
[u"The Dormouse's story", u"The Dormouse's story"]
def is_the_only_string_within_a_tag(s):
""Return True if this string is the only child of its parent tag.""
return (s == s.parent.string)
soup.find_all(string=is_the_only_string_within_a_tag)
# [u"The Dormouse's story", u"The Dormouse's story", u'Elsie', u'Lacie', u'Tillie', u'...']
虽然 string 参数用于搜索字符串,还可以与其它参数混合使用来过滤tag.Beautiful Soup会找到 .string 方法与 string 参数值相符的tag.下面代码用来搜索内容里面包含“Elsie”的标签:
soup.find_all("a", string="Elsie")
# [<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>]
limit 参数
find_all() 方法返回全部的搜索结构,如果文档树很大那么搜索会很慢.如果我们不需要全部结果,可以使用 limit 参数限制返回结果的数量.效果与SQL中的limit关键字类似,当搜索到的结果数量达到 limit 的限制时,就停止搜索返回结果.
文档树中有3个tag符合搜索条件,但结果只返回了2个,因为我们限制了返回数量:
soup.find_all("a", limit=2)
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
recursive 参数
调用tag的 find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点,如果只想搜索tag的直接子节点,可以使用参数 recursive=False .
一段简单的文档:
<html>
<head>
<title>
The Dormouse's story
</title>
</head>
...
是否使用 recursive 参数的搜索结果:
soup.html.find_all("title")
# [<title>The Dormouse's story</title>]
soup.html.find_all("title", recursive=False)
# []
这是文档片段
<html>
<head>
<title>
The Dormouse's story
</title>
</head>
...
Beautiful Soup 提供了多种DOM树搜索方法. 这些方法都使用了类似的参数定义. 比如这些方法: find_all(): name, attrs, text, limit. 但是只有 find_all() 和 find() 支持 recursive 参数.
像调用 find_all() 一样调用tag
find_all() 几乎是Beautiful Soup中最常用的搜索方法,所以我们定义了它的简写方法. BeautifulSoup 对象和 tag 对象可以被当作一个方法来使用,这个方法的执行结果与调用这个对象的 find_all() 方法相同,下面两行代码是等价的:
soup.find_all("a")
soup("a")
这两行代码也是等价的:
soup.title.find_all(string=True)
soup.title(string=True)
find()
find( name , attrs , recursive , string , **kwargs )
find_all() 方法将返回文档中符合条件的所有tag,尽管有时候我们只想得到一个结果.比如文档中只有一个<body>标签,那么使用 find_all() 方法来查找<body>标签就不太合适, 使用 find_all 方法并设置 limit=1 参数不如直接使用 find() 方法.下面两行代码是等价的:
soup.find_all('title', limit=1)
# [<title>The Dormouse's story</title>]
soup.find('title')
# <title>The Dormouse's story</title>
唯一的区别是 find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回结果.
find_all() 方法没有找到目标是返回空列表, find() 方法找不到目标时,返回 None .
print(soup.find("nosuchtag"))
# None
soup.head.title 是 tag的名字 方法的简写.这个简写的原理就是多次调用当前tag的 find() 方法:
soup.head.title
# <title>The Dormouse's story</title>
soup.find("head").find("title")
# <title>The Dormouse's story</title>
CSS选择器
Beautiful Soup支持大部分的CSS选择器,在 Tag 或 BeautifulSoup 对象的 .select() 方法中传入字符串参数, 即可使用CSS选择器的语法找到tag:
soup.select("title")
# [<title>The Dormouse's story</title>]
soup.select("p nth-of-type(3)")
# [<p class="story">...</p>]
通过tag标签逐层查找:
soup.select("body a")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.select("html head title")
# [<title>The Dormouse's story</title>]
找到某个tag标签下的直接子标签 [6] :
soup.select("head > title")
# [<title>The Dormouse's story</title>]
soup.select("p > a")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.select("p > a:nth-of-type(2)")
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
soup.select("p > #link1")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
soup.select("body > a")
# []
找到兄弟节点标签:
soup.select("#link1 ~ .sister")
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.select("#link1 + .sister")
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
通过CSS的类名查找:
soup.select(".sister")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.select("[class~=sister]")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
通过tag的id查找:
soup.select("#link1")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
soup.select("a#link2")
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
同时用多种CSS选择器查询元素:
soup.select("#link1,#link2")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
通过是否存在某个属性来查找:
soup.select('a[href]')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
通过属性的值来查找:
soup.select('a[href="http://example.com/elsie"]')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
soup.select('a[href^="http://example.com/"]')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.select('a[href$="tillie"]')
# [<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.select('a[href*=".com/el"]')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
通过语言设置来查找:
multilingual_markup = """
<p lang="en">Hello</p>
<p lang="en-us">Howdy, y'all</p>
<p lang="en-gb">Pip-pip, old fruit</p>
<p lang="fr">Bonjour mes amis</p>
"""
multilingual_soup = BeautifulSoup(multilingual_markup)
multilingual_soup.select('p[lang|=en]')
# [<p lang="en">Hello</p>,
# <p lang="en-us">Howdy, y'all</p>,
# <p lang="en-gb">Pip-pip, old fruit</p>]
返回查找到的元素的第一个
soup.select_one(".sister")
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
对于熟悉CSS选择器语法的人来说这是个非常方便的方法.Beautiful Soup也支持CSS选择器API, 如果你仅仅需要CSS选择器的功能,那么直接使用 lxml 也可以, 而且速度更快,支持更多的CSS选择器语法,但Beautiful Soup整合了CSS选择器的语法和自身方便使用API.
爬虫数据处理模块——json
json.loads(json)
- 作用
把json格式的字符串转为Python数据类型
- 示例
html_json = json.loads(res.text)
json.dump(python,f,ensure_ascii=False)
- 作用
把python数据类型转为 json格式的字符串
注意:一般让你把抓取的数据保存为json文件时使用
- 参数说明
第1个参数: python类型的数据(字典,列表等)
第2个参数: 文件对象
第3个参数: ensure_ascii=False # 序列化时编码
- 示例
# 示例1
import json
item = {'name':'QQ','app_id':1}
with open('小米.json','a') as f:
json.dump(item,f,ensure_ascii=False)
# 示例2
import json
item_list = []
for i in range(3):
item = {'name':'QQ','id':i}
item_list.append(item)
with open('xiaomi.json','a') as f:
json.dump(item_list,f,ensure_ascii=False)
json.dumps(python)
- 作用
把 python 类型 转为 json 类型
- 示例
import json
# json.dumps()之前
item = {'name':'QQ','app_id':1}
print('before dumps',type(item)) # dict
# json.dumps之后
item = json.dumps(item)
print('after dumps',type(item)) # str
json.load(f)
作用
将json文件读取,并转为python类型
示例
import json
with open('D:\\spider_test\\xiaomi.json','r') as f:
data = json.load(f)
print(data)
json模块总结
# 爬虫最常用
1、数据抓取 - json.loads(html)
将响应内容由: json 转为 python
2、数据保存 - json.dump(item_list,f,ensure_ascii=False)
将抓取的数据保存到本地 json文件
# 抓取数据一般处理方式
1、txt文件
2、csv文件
3、json文件
4、MySQL数据库
5、MongoDB数据库
6、Redis数据库
爬虫数据持久化存储——写入文件
open方法
-
方法名称及参数
**open(file, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True)** **file** 文件的路径,需要带上文件名包括文件后缀(c:\\1.txt) **mode** 打开的方式(r,w,a,x,b,t,r+,w+,a+,U) **buffering** 缓冲的buffering大小, 0,就不会有寄存。1,寄存行。大于 1 的整数,寄存区的缓冲大小。负值,寄存区的缓冲大小为系统默认。 **encoding** 文件的编码格式(utf-8,GBK等) -
常用的文件打开方式
r 以只读方式打开文件。文件的指针会放在文件的开头。 w 以写入方式打开文件。文件存在覆盖文件,文件不存在创建一个新文件。 a 以追加方式打开文件。如果文件已存在,文件指针放在文件末尾。如果文件不存在,创建新文件并可写入。 r+ 打开一个文件用于读写。文件指针会放在文件的开头 w+ 打开一个文件用于读写。文件存在覆盖文件,文件不存在创建一个新文件。 a+ 打开一个文件用于读写。如果文件已存在,文件指针放在文件末尾。如果文件不存在,创建新文件并可写入。 记忆方法:记住r读,w写,a追加,每个模式后加入+号就变成可读写。
文件的读取及写入
读取文件
file.read([size]):读取文件(读取size个字节,默认读取全部)
file.readline()):读取一行
file.readlines():读取完整的文件,返回每一行所组成的列表
写入文件
file.write(str):将字符串写入文件
file.writelines(lines):将多行文本写入文件中,lines为字符串组成的列表或元组
爬虫数据持久化存储——csv文件
作用
将爬取的数据存放到本地的csv文件中
使用流程
1、导入模块
2、打开csv文件
3、初始化写入对象
4、写入数据(参数为列表)
import csv
with open('film.csv','w') as f:
writer = csv.writer(f)
writer.writerow([])
示例:创建 test.csv 文件,在文件中写入数据
# 单行写入(writerow([]))
import csv
with open('test.csv','w',newline='') as f:
writer = csv.writer(f)
writer.writerow(['步惊云','36'])
writer.writerow(['超哥哥','25'])
# 多行写入(writerows([(),(),()]
import csv
with open('test.csv','w',newline='') as f:
writer = csv.writer(f)
writer.writerows([('聂风','36'),('秦霜','25'),('孔慈','30')])
爬虫数据处理:操作数据库模块——pymysql
pymysql介绍
PyMySQL是在 Python3.x 版本中用于连接 MySQL 服务器的一个库,Python2中是使用mysqldb
pymysql安装
pip install pymysql -i https://pypi.douban.com/simple
pymysql基本使用
# 导入pymysql模块
import pymysql
# 连接database
conn = pymysql.connect(
host=“你的数据库地址”,
user=“用户名”,password=“密码”,
database=“数据库名”,
charset=“utf8”)
# 得到一个可以执行SQL语句的光标对象
cursor = conn.cursor() # 执行完毕返回的结果集默认以元组显示
# 得到一个可以执行SQL语句并且将结果作为字典返回的游标
#cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
# 定义要执行的SQL语句
sql = """
CREATE TABLE USER1 (
id INT auto_increment PRIMARY KEY ,
name CHAR(10) NOT NULL UNIQUE,
age TINYINT NOT NULL
)ENGINE=innodb DEFAULT CHARSET=utf8; #注意:charset='utf8' 不能写成utf-8
"""
# 执行SQL语句
cursor.execute(sql)
# 关闭光标对象
cursor.close()
# 关闭数据库连接
conn.close()
增删改查操作
添加一条或多条数据
#假设已有某数据库xing,其中包含姓名及编号两个字段
import pymysql
conn = pymysql.connect(
host='192.168.0.103',
port=3306,
user='root',
password='123',
database='xing',
charset='utf8'
)
# 获取一个光标
cursor = conn.cursor()
# 定义要执行的sql语句
sql = 'insert into userinfo(user,pwd) values(%s,%s);'
data = [
('july', '147'),
('june', '258'),
('marin', '369')
]
# 拼接并执行sql语句
cursor.executemany(sql, data)
# 涉及写操作要注意提交
conn.commit()
# 关闭连接
cursor.close()
conn.close()
插入单条数据
import pymysql
conn =pymysql.connect(
host ='192.168.0.103',
port = 3306,
user = 'root',
password ='123',
database ='xing',
charset ='utf8'
)
cursor =conn.cursor() #获取一个光标
sql ='insert into userinfo (user,pwd) values (%s,%s);'
name = 'wuli'
pwd = '123456789'
cursor.execute(sql, [name, pwd])
conn.commit()
cursor.close()
conn.close()
获取最新插入数据
import pymysql
# 建立连接
conn = pymysql.connect(
host="192.168.0.103",
port=3306,
user="root",
password="123",
database="xing",
charset="utf8"
)
# 获取一个光标
cursor = conn.cursor()
# 定义将要执行的SQL语句
sql = "insert into userinfo (user, pwd) values (%s, %s);"
name = "wuli"
pwd = "123456789"
# 并执行SQL语句
cursor.execute(sql, [name, pwd])
# 涉及写操作注意要提交
conn.commit()
# 关闭连接
# 获取最新的那一条数据的ID
last_id = cursor.lastrowid
print("最后一条数据的ID是:", last_id)
cursor.close()
conn.close()
删除操作
import pymysql
# 建立连接
conn = pymysql.connect(
host="192.168.0.103",
port=3306,
user="root",
password="123",
database="xing",
charset="utf8"
)
# 获取一个光标
cursor = conn.cursor()
# 定义将要执行的SQL语句
sql = "delete from userinfo where user=%s;"
name = "june"
# 拼接并执行SQL语句
cursor.execute(sql, [name])
# 涉及写操作注意要提交
conn.commit()
# 关闭连接
cursor.close()
conn.close()
更新数据
import pymysql
# 建立连接
conn = pymysql.connect(
host="192.168.0.103",
port=3306,
user="root",
password="123",
database="xing",
charset="utf8"
)
# 获取一个光标
cursor = conn.cursor()
# 定义将要执行的SQL语句
sql = "delete from userinfo where user=%s;"
name = "june"
# 拼接并执行SQL语句
cursor.execute(sql, [name])
# 涉及写操作注意要提交
conn.commit()
# 关闭连接
cursor.close()
conn.close()
查询数据
# 可以获取指定数量的数据
cursor.fetchmany(3)
# 光标按绝对位置移动1
cursor.scroll(1, mode="absolute")
# 光标按照相对位置(当前位置)移动1
cursor.scroll(1, mode="relative"
爬虫数据持久化存储——写入MySQL
1、在数据库中建库建表
# 连接到mysql数据库
mysql -h127.0.0.1 -uroot -p123456
# 建库建表
create database maoyandb charset utf8;
use maoyandb;
create table filmtab(
name varchar(100),
star varchar(300),
time varchar(50)
)charset=utf8;
- 2、回顾pymysql基本使用
一般方法:
import pymysql
# 创建2个对象
db = pymysql.connect('localhost','root','123456','maoyandb',charset='utf8')
cursor = db.cursor()
# 执行SQL命令并提交到数据库执行
# execute()方法第二个参数为列表传参补位
ins = 'insert into filmtab values(%s,%s,%s)'
cursor.execute(ins,['霸王别姬','张国荣','1993'])
db.commit()
# 关闭
cursor.close()
db.close()
- 来试试高效的executemany()方法?
import pymysql
# 创建2个对象
db = pymysql.connect('192.168.153.137','tiger','123456','maoyandb',charset='utf8')
cursor = db.cursor()
# 抓取的数据
film_list = [('月光宝盒','周星驰','1994'),('大圣娶亲','周星驰','1994')]
# 执行SQL命令并提交到数据库执行
# execute()方法第二个参数为列表传参补位
cursor.executemany('insert into filmtab values(%s,%s,%s)',film_list)
db.commit()
# 关闭
cursor.close()
db.close()
案例:将top100榜单电影信息存入MySQL数据库(尽量使用executemany方法)
参见代码:Spider_Codes/demo03_MaoYanMovie_OOP_mysql.py
参见代码:Spider_Codes/demo03_MaoYanMovie_OOP_mysql_executemany.py
爬虫数据持久化存储——写入MongoDB
- pymongo操作mongodb数据库
import pymongo
# 1.数据库连接对象
conn=pymongo.MongoClient('localhost',27017)
# 2.库对象
db = conn['库名']
# 3.集合对象
myset = db['集合名']
# 4.插入数据
myset.insert_one({字典})
- mongodb常用命令
mongo
>show dbs
>use 库名
>show collections
>db.集合名.find().pretty()
>db.集合名.count()
>db.dropDatabase()




