
Python爬虫笔记3:爬虫基础进阶
作者:Barranzi_
个人github主页:[github](https://github.com/La0bALanG)
个人邮箱:awc19930818@outlook.com
新时代的铁饭碗:一辈子不管走到哪里都有饭吃(还能吃上热乎的)。——佚名
免责声明:
本系列笔记撰写初衷就是为了分享个人知识以及个人学习历程中的感悟及思考,所涉及到的内容`仅供学习与交流`,请勿用作`非法或商业用途`!由此引发的任何法律纠纷`后果自负`,与作者本人无关!
版权声明:
未经作者本人授权,禁止转载!请尊重原创!

注:本文所有代码、案例测试环境:1.Linux -- 系统版本:Ubuntu20.04 LTS 2.windows -- 系统版本:WIN10 64位家庭版
常见反爬机制1:代理IP
- 定义及作用
- 定义: 代替你原来的IP地址去对接网络的IP地址
- 作用: 隐藏自身真实IP,避免被封
- 获取代理IP的网站
- 西刺代理、快代理、全网代理、代理精灵、… …
- 代理IP的分类
- 透明代理: 服务端能看到 - (用户真实IP 以及 代理IP)
- 普通代理: 服务端能看到 - (代理IP,知道有人通过此代理IP访问了网站,但不知用户真实IP)
- 高匿代理: 服务端能看到 - (代理IP)
- 常用代理IP类型的特点
- 普通代理: 可用率低、速度慢、不稳定、免费或价格便宜
- 私密代理: 可用率高、速度较快、价格适中、爬虫常用
- 独享代理: 可用率极高、速度快、价格贵
普通代理
- 获取代理IP网站
西刺代理、快代理、全网代理、代理精灵、… …
- 参数类型
1、语法结构
proxies = {
'协议':'协议://IP:端口号'
}
2、示例
proxies = {
'http':'http://IP:端口号',
'https':'https://IP:端口号'
}
- 示例
使用免费普通代理IP访问测试网站: http://httpbin.org/get
import requests
url = 'http://httpbin.org/get'
headers = {
'User-Agent':'Mozilla/5.0'
}
# 定义代理,在代理IP网站中查找免费代理IP
proxies = {
'http':'http://112.85.164.220:9999',
'https':'https://112.85.164.220:9999'
}
html = requests.get(url,proxies=proxies,headers=headers,timeout=5).text
print(html)
思考: 建立一个自己的代理IP池,随时更新用来抓取网站数据
- 需求:
- 从免费代理IP网站上,抓取免费代理IP
- 测试抓取的IP,可用的保存在文件中
代码实现
# -*- coding:utf-8 _*-
"""
@version:
author:安伟超
@time: 2020/09/12
@file: demo10_xicidaili_getIP.py.py
@environment:virtualenv
@email:awc19930818@outlook.com
@github:https://github.com/La0bALanG
@requirement:爬取66代理所有可用代理IP,存入文件,作为个人IP代理池
"""
import threading
import requests
import time
import random
from lxml import etree
from fake_useragent import UserAgent
class GetXiCiDaiLiIPSpider(object):
'''
面向对象思路:
1.拆分功能细节。整体程序可拆分为:
1.发请求获得页面
2.解析页面
3.持久化存储(写入文件保存)
2.结合开闭原则,封装功能方法为私有方法,对外提供统一公共接口
3.采用单例模式:假设本爬虫程序在多个时间、不同情况下多次使用,单例模式实现只创建一个对象,提升性能避免内存占用过高。
'''
_instance_lock = threading.Lock()
# 单例模式实现:__new__方法
def __new__(cls, *args, **kwargs):
if not hasattr(GetXiCiDaiLiIPSpider, '_instance'):
with GetXiCiDaiLiIPSpider._instance_lock:
if not hasattr(GetXiCiDaiLiIPSpider, '_instance'):
GetXiCiDaiLiIPSpider._instance = object.__new__(cls)
return GetXiCiDaiLiIPSpider._instance
def __init__(self):
self.__url = 'https://www.kuaidaili.com/free/inha/{}/'
self.__headers = {
'User-Agent':UserAgent().random
}
def __get_html(self,url,headers):
return requests.get(url=url,headers=headers).text
def __parse_html(self,html):
dom = etree.HTML(html)
tr_lists = dom.xpath('//table/tbody/tr')
#第一个tr不是ip及端口号信息,跳过第1个,从第2个tr开始提取
for tr in tr_lists:
ip = tr.xpath('./td[1]/text()')[0]
port = tr.xpath('./td[2]/text()')[0]
self.__test_IP(ip,port)
def __test_IP(self,ip,port):
proxies = {
'http': 'http://{}:{}'.format(ip, port),
'https': 'https://{}:{}'.format(ip, port),
}
test_url = 'https://www.hao123.com/'
try:
res = requests.get(url=test_url,proxies=proxies,timeout=8)
if res.status_code == 200:
print('代理ip:%s:%s测试完毕,success,采用,即将写入代理池文件'%(ip,port))
with open('proxies.txt','a') as f:
print('写入代理ip...')
f.write(ip + ':' + port + '\n')
print('写入完成,测试下一条代理ip...')
except Exception as e:
print('代理ip:%s:%s测试完毕,faild,不采用,测试下一条代理ip...'%(ip,port))
def display(self):
begin = int(input('请输入开始页数:'))
end = int(input('请输入结束页数:'))
for i in range(begin,end + 1):
print('开始爬取第%d页代理ip...'%i)
url = self.__url.format(i)
self.__parse_html(self.__get_html(url,self.__headers))
time.sleep(random.randint(0,3))
def test():
GetXiCiDaiLiIPSpider().display()
if __name__ == '__main__':
test()
私密代理+独享代理
- 语法格式
1、语法结构
proxies = {
'协议':'协议://用户名:密码@IP:端口号'
}
2、示例
proxies = {
'http':'http://用户名:密码@IP:端口号',
'https':'https://用户名:密码@IP:端口号'
}
- 示例代码
import requests
url = 'http://httpbin.org/get'
proxies = {
'http': 'http://用户名:密码@106.75.71.140:16816',
'https':'https://用户名:密码@106.75.71.140:16816',
}
headers = {
'User-Agent' : 'Mozilla/5.0',
}
html = requests.get(url,proxies=proxies,headers=headers,timeout=5).text
print(html)
常见反爬机制2:动态页面爬虫技术
控制台抓包思路
-
静态页面
一种常见的网站、网页类型。我们爬虫所关注的特点是:该类网站的一次html请求的response中包含部分或所有所需的目标数据。
注意:静态网页目前来看存在于:
- 确确实实没什么技术含量的小网站…
- 对安全性关注度不高的某些数据,采用静态页面直接渲染出来。
特点:此类静态页面包含的数据对企业或机构来说无关痛痒,即不是那么的重要,而静态页面直接渲染的方式相对来说对技术要求又不高,成本较低,所以直接渲染出来,你爱爬你就爬~无所谓~
-
动态网页
一种常见的网站、网页类型。此类网页才是WWW中最常见的网页。基本现在但凡是个规模的网站,大部分都采用了动态页面技术。动态页面不会将数据直接渲染在response中,且不会一次刷新就全部加载完毕,而是伴随用户对页面的操作实现局部刷新。
动态页面的核心特点是:
- 数据不会直接渲染于response中;
- 大部分动态页面都会采用AJAX异步请求进行局部刷新;
- 结合以上特点,对响应的数据进行处理,通常采用js进行加载,且处理过程通常伴随着加密。
所以,动态页面在爬取的过程中难度就增大了,不仅要对响应页面做处理,更重要的是要追踪js加载方式甚至追踪js代码,深层次剖析请求及响应的数据体,进而采用Python进行模拟js操作,实现获取真实数据及破解加密。
-
如何判断一个页面是静态页面还是动态页面?
一般具有以下几个特征的页面,基本就是动态页面了:
- 页面伴随着一些鼠标键盘操作一点点刷新数据的。比如最常见的“加载更多”;
- 在elements中能解析到数据,但进入具体的response中却查找不到数据的;
- 采用AJAX异步加载的。
-
html的response中不存在所需数据怎么办?
如果当前页面的html请求的response中不存在所需数据,但elements选项中能够使用re或xpath解析到我们所需要的数据,则所需数据一定是进行了响应处理,则可以通过控制台抓包分析查找所需数据。
-
控制台抓包分析
- 打开浏览器,F12打开控制台,找到Network选项卡
- 控制台常用选项
- Network: 抓取网络数据包
- ALL: 抓取所有的网络数据包
- XHR:抓取异步加载的网络数据包
- JS : 抓取所有的JS文件
- Sources: 格式化输出并打断点调试JavaScript代码,助于分析爬虫中一些参数
- Console: 交互模式,可对JavaScript中的代码进行测试
- Network: 抓取网络数据包
- 抓取具体网络数据包后
- 单击左侧网络数据包地址,进入数据包详情,查看右侧
- 右侧:
- Headers: 整个请求信息:General、Response Headers、Request Headers、Query String、Form Data
- Preview: 对响应内容进行预览
- Response:响应内容
动态加载页面的数据爬取-AJAX
-
什么是AJAX
AJAX(Asynchronous JavaScript And XML):异步的JavaScript and XML。通过在后台与服务器进行商量的数据交换,Ajax可以使网页实现异步更新,这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。传统的网页(不使用Ajax)如果需要更新内容,必须重载整个网页页面。又因为传统的数据传输格式使用的是XML语法,因此叫做Ajax。但现如今的数据交互方式,基本上都选择使用JSON格式的字符串,其目的就是为了达到数据传输格式的统一。因为json支持几乎所有编程语言。使用Ajax加载的数据,即使有对应的JS脚本,能够将数据渲染到浏览器中,在查看网页源码时还是不能看到通过Ajax加载的数据,只能看到使用这个url加载的HTML代码。
-
什么是JSON
JSON(JavaScript Object Notation, JS对象简谱) 是一种轻量级的数据交换格式。它基于 ECMAScript (欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
-
动态页面的数据加载特征
- 几乎统一采用json格式字符串传递;
- 往往伴随着用户对网页的某些操作,比如鼠标事件,键盘事件等;
- 几乎无法直接在html的response中直观看到数据;
-
动态页面数据抓取固定套路
- 请求目标url;
- F12打开控制台进行抓包分析;F12 – network – XHR/JS – 网页操作 – / 查看新增请求项 – 分析数据及规律
- 确定目标数据url/接口
- 发请求,获得response;
- 解析数据(大部分情况下解析的是json数据)
- 持久化存储
案例:破解有道翻译实现中英文单词互译
参见代码:Spider_Codes/demo08_YouDaoTransforSpider_OOP.py
思考:手动修改headers或form表单数据相对麻烦,是否有简便的方式?
借助正则表达式处理headers,方便快速修改格式并使用。
参见代码:[Spider_Code/demo09_re_headers_and_formData.py
举个栗子:
headers:
"""
Accept: application/json, text/javascript, */*; q=0.01
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Connection: keep-alive
Content-Length: 248
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Cookie: OUTFOX_SEARCH_USER_ID=1559141275@10.169.0.83; JSESSIONID=aaaUEr86rzfeo7xp8b7rx; OUTFOX_SEARCH_USER_ID_NCOO=1009771993.8014448; ___rl__test__cookies=1599804152408
Host: fanyi.youdao.com
Origin: http://fanyi.youdao.com
Referer: http://fanyi.youdao.com/
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36
X-Requested-With: XMLHttpRequest
"""
form表单数据:
"""
i: 朋友
from: zh-CHS
to: en
smartresult: dict
client: fanyideskweb
salt: 15998041524052
sign: bf3ecd8f4c8a282ed79468f49aeb69fd
lts: 1599804152405
bv: e915c77f633538e8cf44c657fe201ebb
doctype: json
version: 2.1
keyfrom: fanyi.web
action: lan-select
"""
# -*- coding:utf-8 _*-
"""
@version:
author:安伟超
@time: 2020/09/11
@file: demo09_re_headers_and_formData.py.py
@environment:virtualenv
@email:awc19930818@outlook.com
@github:https://github.com/La0bALanG
@requirement:使用正则表达式预处理headers及form表单数据
"""
import re
class demoSpider(object):
def __init__(self):
self.__headers = """
Accept: application/json, text/javascript, */*; q=0.01
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Connection: keep-alive
Content-Length: 248
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Cookie: OUTFOX_SEARCH_USER_ID=1559141275@10.169.0.83; JSESSIONID=aaaUEr86rzfeo7xp8b7rx; OUTFOX_SEARCH_USER_ID_NCOO=1009771993.8014448; ___rl__test__cookies=1599804152408
Host: fanyi.youdao.com
Origin: http://fanyi.youdao.com
Referer: http://fanyi.youdao.com/
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36
X-Requested-With: XMLHttpRequest
"""
self.__formData = """
i: 朋友
from: zh-CHS
to: en
smartresult: dict
client: fanyideskweb
salt: 15998041524052
sign: bf3ecd8f4c8a282ed79468f49aeb69fd
lts: 1599804152405
bv: e915c77f633538e8cf44c657fe201ebb
doctype: json
version: 2.1
keyfrom: fanyi.web
action: lan-select
"""
def re_parse(self,str_data):
dict = {}
for x,y in re.findall('(.*):(.*)',str_data):
dict[x] = y.strip()
return dict
def display(self):
headers = self.re_parse(self.__headers)
form_data = self.re_parse(self.__formData)
print(headers)
print(form_data)
demoSpider().display()
总结:常见基本反制爬虫策略(反爬机制)及处理方式
- Headers反爬虫 :Cookie、Referer、User-Agent
- 解决方案: 通过F12获取headers,传给requests.get()方法
- IP限制 :网站根据IP地址访问频率进行反爬,短时间内限制IP访问
- 解决方案:
- 构造自己IP代理池,每次访问随机选择代理,经常更新代理池
- 购买开放代理或私密代理IP
- 降低爬取的速度
- 解决方案:
- User-Agent限制 :类似于IP限制
- 解决方案: 构造自己的User-Agent池,每次访问随机选择
- 对响应内容做处理
- 解决方案: 打印并查看响应内容,用xpath或正则做处理
- 动态页面技术:采用AJAX异步加载数据包,增加数据获取难度
- 解决方案:借助控制台、fiddler或其他抓包工具抓取XHR数据包,分析其请求URL及参数,最终确定所需数据的获取方式
案例:民政部网站抓取2020年全国最新行政区划代码
参见代码:Spider_Codes/demo11_GetGovementAdministrativeArea_OOP.py
参见代码:Spider_Codes/demo11_GetGovementAdministrativeArea_Increment_OOP.py
案例:豆瓣电影评分数据抓取
参见代码:Spider_Codes/demo12_DouBanMovieComments_OOP.py
自动化测试工具Selenium + Webdriver模拟浏览器操作
selenium介绍
简介
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
注意:selenium只是一个工具,必须与第三方浏览器结合才能使用。
安装
pip install selenium
phantomjs浏览器
无界面浏览器(又称无头浏览器),在内存中进行页面加载,高效.
PhantomJS的适用范围就是无头浏览器的适用范围。通常无头浏览器可以用于页面自动化,网页监控,网络爬虫等:
- 页面自动化测试:希望自动的登陆网站并做一些操作然后检查结果是否正常。
- 网页监控:希望定期打开页面,检查网站是否能正常加载,加载结果是否符合预期。加载速度如何等。
- 网络爬虫:获取页面中使用js来下载和渲染信息,或者是获取链接处使用js来跳转后的真实地址。
phantomjs、chromedriver、geckodriver安装
下载地址:
1、chromedriver : 下载对应版本 http://chromedriver.storage.googleapis.com/index.html
2、geckodriver https://github.com/mozilla/geckodriver/releases
3、phantomjs https://phantomjs.org/download.html
安装:
windows:
1.phantomjs:下载后解压到某目录,直接将其路径添加进系统path环境变量即可。
2.chromedriver、geckodriver :把解压后得到的chromedriver.exe、GeckoDriver.exe拷贝到python安装目录的Scripts目录下(添加到系统环境变量)
查看python安装路径: where python
Linux:
1、下载后解压 tar -zxvf geckodriver.tar.gz
2、拷贝解压后文件到 /usr/bin/ (添加环境变量) sudo cp geckodriver /usr/bin/
3、更改权限 sudo -i cd /usr/bin/ chmod 777 geckodriver
简单示例:使用selenium+浏览器打开百度首页
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.quit()
浏览器对象方法
常用基本方法
加载浏览器驱动: webdriver.Firefox()
打开页面:get()
关闭浏览器:quit()
最大化窗口: maximize_window()
设置窗口参数:set_window_size(600,800)
后退到前一页: back()
前进到后一页: forward()
刷新页面: refresh()
获得title并打印:title
元素定位方法
单元素定位
id定位:find_element_by_id()
name定位:find_element_by_name()
class定位:find_element_by_class_name()
tag定位:find_element_by_tag_name()
link定位:find_element_by_link_text()
partial link 定位: find_element_by_partial_link_text()
Xpath定位:
绝对路径:find_element_by_xpath("绝对路径")
元素属性:find_element_by_xpath("//unput[@id='kw']")
层级与属性结合:find_element_by_xpath("//form[@id='loginForm']/ul/input[1]")
逻辑运算符:find_element_by_xpath("//input[@id='kw' and@class='s_ipt']")
CSS定位:find_element_by_css_selector(选择器)
多元素定位
browser.find_elements_by_id('')
browser.find_elements_by_name('')
browser.find_elements_by_class_name('')
browser.find_elements_by_xpath('')
... ...
节点对象操作
ele.send_keys('') # 搜索框发送内容
ele.click()
ele.text # 获取文本内容,包含子节点和后代节点的文本内容
ele.get_attribute('src') # 获取属性值
键盘事件方法
from selenium.webdriver.common.keys import Keys
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')
# 1、在搜索框中输入"selenium"
browser.find_element_by_id('kw').send_keys('赵丽颖')
# 2、输入空格
browser.find_element_by_id('kw').send_keys(Keys.SPACE)
# 3、Ctrl+a 模拟全选
browser.find_element_by_id('kw').send_keys(Keys.CONTROL, 'a')
# 4、Ctrl+c 模拟复制
browser.find_element_by_id('kw').send_keys(Keys.CONTROL, 'c')
# 5、Ctrl+v 模拟粘贴
browser.find_element_by_id('kw').send_keys(Keys.CONTROL, 'v')
# 6、输入回车,代替 搜索 按钮
browser.find_element_by_id('kw').send_keys(Keys.ENTER)
鼠标事件方法
from selenium import webdriver
# 导入鼠标事件类
from selenium.webdriver import ActionChains
driver = webdriver.Chrome()
driver.get('http://www.baidu.com/')
#移动到 设置,perform()是真正执行操作,必须有
element = driver.find_element_by_xpath('//*[@id="u1"]/a[8]')
ActionChains(driver).move_to_element(element).perform()
#单击,弹出的Ajax元素,根据链接节点的文本内容查找
driver.find_element_by_link_text('高级搜索').click()
selenium切换页面
页面中点开链接出现新的页面,但是浏览器对象browser还是之前页面的对象
# 获取当前所有句柄(窗口)
all_handles = browser.window_handles
# 切换browser到新的窗口,获取新窗口的对象
browser.switch_to.window(all_handles[1])
iframe子框架
网页中嵌套了网页,先切换到iframe子框架,然后再执行其他操作
browser.switch_to.iframe(iframe_element)
多进程、多线程爬虫技术
- 意义:充分利用计算机CPU的多核资源,同时处理多个应用程序任务,以便提高程序的运行效率。
- 实现方案:多进程、多线程
进程(Process)理论基础
定义
- 程序在计算机中的一次运行。
- 程序是一个可执行文件,以静态的方式占有磁盘空间。
- 进程是一个动态的过程描述,占有计算机的运行资源,有一定的生命周期。
系统如何产生一个进程
- 用户空间通过调用程序接口或者命令发起请求
- 操作系统接受用户请求,开始创建进程
- 操作系统调配计算机资源,确定进程状态等
- 操作系统将创建的进程提供给用于使用
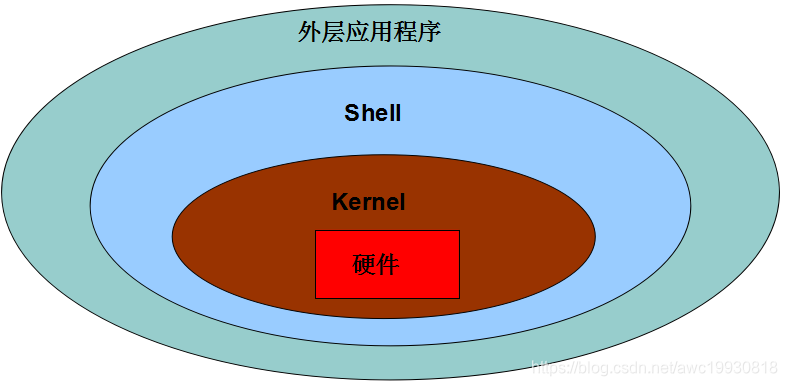
进程基本概念
- CPU时间片:如果一个进程占有CPU内核则称这个进程在CPU时间片上。
- PCB:进程控制块,在内存中开辟的一块存储空间,用于存放进程的基本信息,也用于系统查找识别进程。
- 进程ID:PID,系统为每个进程分配的一个大于0的证书,作为进程ID。每个进程ID是不可能重复的。
- 父子进程:系统中每一个进程(除了系统初始化进程)都有唯一的父进程,可以有0个或多个子进程。父子进程关系便于进程管理
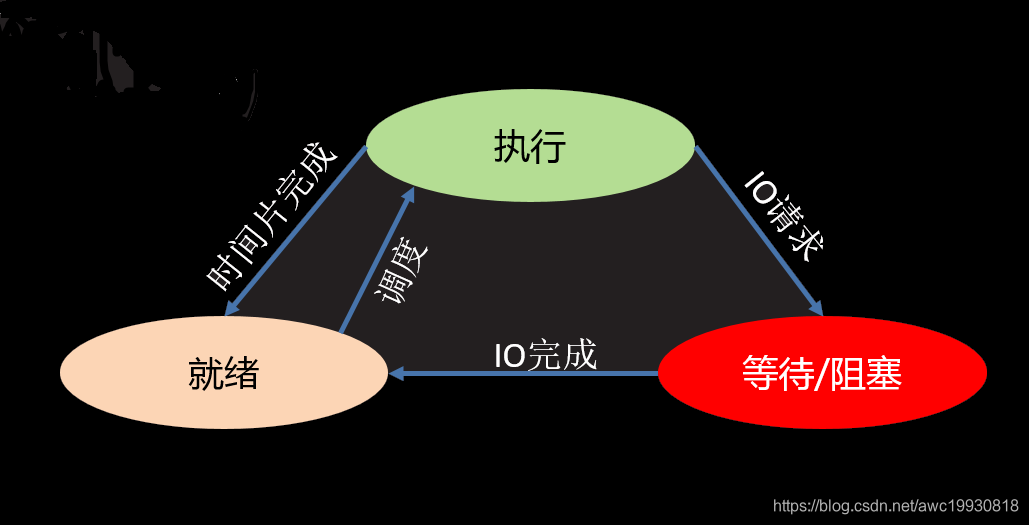
- 进程状态
- 三态
- 就绪态:进程具备执行条件,等待分配cpu资源
- 运行态:进程占有cpu时间片正在运行
- 等待态:进程暂时停止运行,让出cpu
- 五态(在三态基础上增加)
- 新建态:创建一个进程,获取资源的过程
- 终止态:进程结束,释放资源的过程
- 状态查看命令:ps -aux –> STAT列
S 等待态 R 执行态 Z 僵尸
- 进程的运行特征
- 多进程可以更充分使用计算机多核资源
- 进程之间的运行互不影响,各自独立
- 每个进程拥有独立的空间,各自使用自己的空间资源
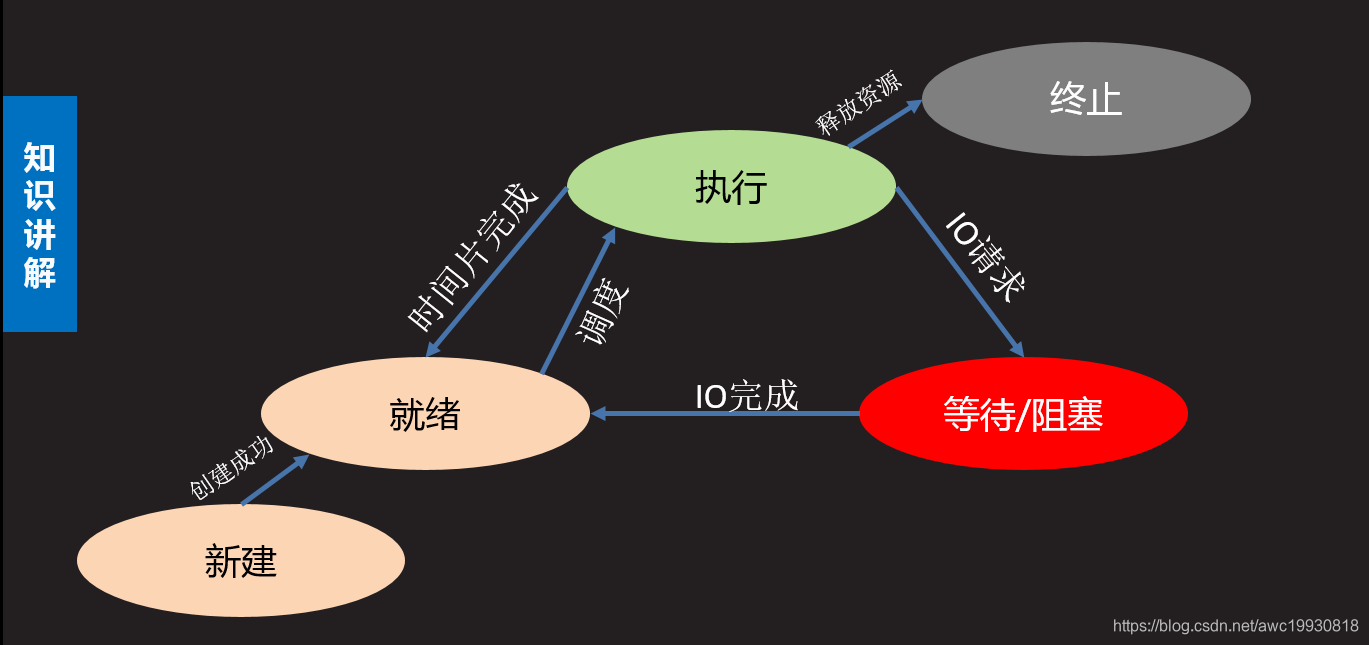
基于fork的多进程
pid = os.fork()
功能: 创建新的进程
返回值:整数,如果创建进程失败返回一个负数,如果成功则在原有进程中返回新进程的PID,在新进程中返回0
注意:
子进程会复制父进程全部内存空间,从fork下一句开始执行。
父子进程各自独立运行,运行顺序不一定。
利用父子进程fork返回值的区别,配合if结构让父子进程执行不同的内容几乎是固定搭配。
父子进程有各自特有特征比如PID PCB 命令集等。
父进程fork之前开辟的空间子进程同样拥有,父子进程对各自空间的操作不会相互影响。
示例代码:
import os
from time import sleep
pid = os.fork()
if pid < 0:
print("进程创建失败")
elif pid == 0:
sleep(3)
print("新的进程")
else:
sleep(4)
print("原来的进程")
print("实验完毕")
进程相关函数
os.getpid()
功能: 获取一个进程的PID值
返回值: 返回当前进程的PID
os.getppid()
功能: 获取父进程的PID号
返回值: 返回父进程PID
os._exit(status)
功能: 结束一个进程
参数:进程的终止状态
sys.exit([status])
功能:退出进程
参数:整数 表示退出状态
字符串 表示退出时打印内容
代码举例:
"""
获取进程的PID值
"""
import os
pid = os.fork()
if pid < 0:
print("Error")
elif pid == 0:
print("Child PID:",os.getpid())
print("Get Parent PID:",os.getppid())
else:
print("Get Child PID:",pid)
print("Parent PID:", os.getpid())
"""
进程退出
"""
import os,sys
# os._exit(0) # 进程退出
sys.exit("Process exit") # 进程退出
print("进程退出")
孤儿进程与僵尸进程
-
孤儿进程:父进程先于子进程退出,此时子进程成为孤儿进程
特点:孤儿进程会被系统进程收养,此时系统进程就会成为孤儿进程新的父进程,孤儿进程退出该进程会自动处理。
-
僵尸进程:子进程先于父进程退出,父进程有没有处理子进程的退出状态,此时子进程就会成为僵尸进程
特点: 僵尸进程虽然结束,但是会存留部分PCB在内存中,大量的僵尸进程会浪费系统的内存资源。
-
如何避免僵尸进程产生
#使用wait函数处理子进程退出
pid,status = os.wait()
功能:在父进程中阻塞等待处理子进程退出
返回值: pid 退出的子进程的PID
status 子进程退出状态
# 通过信号处理子进程退出
#使用signal模块在父进程创建子进程前写如下语句 :
import signal
signal.signal(signal.SIGCHLD,signal.SIG_IGN)
#特点:非阻塞,不会影响父进程运行,可以处理所有子进程退出
multiprocessing 模块创建进程
基本语法
Process()
功能 : 创建进程对象
参数 : target 绑定要执行的目标函数
args 元组,用于给target函数位置传参
kwargs 字典,给target函数键值传参
p.start()
功能 : 启动进程
注意:启动进程此时target绑定函数开始执行,该函数作为子进程执行内容,此时进程真正被创建
p.join([timeout])
功能:阻塞等待回收进程
参数:超时时间
注意
- 使用multiprocessing创建进程同样是子进程复制父进程空间代码段,父子进程运行互不影响。
- 子进程只运行target绑定的函数部分,其余内容均是父进程执行内容。
- multiprocessing中父进程往往只用来创建子进程回收子进程,具体事件由子进程完成。
- multiprocessing创建的子进程中无法使用标准输入
代码举例1:
"""
multiprocessing 模块创建进程
【1】 将需要子进程执行的事件封装为函数
【2】 通过模块的Process类创建进程对象,关联函数
【3】 通过进程对象调用start启动进程
【4】 通过进程对象调用join回收进程
"""
from time import sleep
import multiprocessing
a = 1
# 进程执行函数
def fun():
print("开始一个进程")
sleep(5)
global a
print("a = ",a)
a = 1000
print("子进程执行结束")
# 创建进程对象
p = multiprocessing.Process(target=fun)
# 启动进程 此时进程诞生 执行函数作为进程的执行内容
p.start()
# 父进程做的
sleep(3)
print("父进程事件")
# 回收进程,防止僵尸进程
p.join(1)
print("==================================")
print("a:",a)
"""
p = os.fork()
if pid == 0:
fun()
os._exit()
else:
os.wait()
"""
代码举例2:
"""
process 示例
"""
from multiprocessing import Process
from time import sleep
# 带有参数的进程函数
def worker(sec,name):
for i in range(3):
sleep(sec)
print("I'm %s"%name)
print("I'm working...")
# 位置传参
# p = Process(target=worker,args=(2,'Lucy'))
# 关键字传参
p = Process(target=worker,args=(2,),kwargs={'name':'Lily'})
p.start()
p.join()
print("======================")
代码举例3:
"""
process 示例 创建多个子进程
"""
from multiprocessing import Process
from time import sleep
import os
def th1():
sleep(3)
print("吃饭")
print(os.getppid(),'--',os.getpid())
def th2():
sleep(2)
print("睡觉")
print(os.getppid(),'--',os.getpid())
def th3():
sleep(4)
print("打豆豆")
print(os.getppid(),'--',os.getpid())
jobs = []
for th in [th1,th2,th3]:
p = Process(target=th)
jobs.append(p) # 保留每一个进程对象
p.start()
for i in jobs:
i.join()
multiprocessing 模块进程创建流程特点:
【1】 将需要子进程执行的事件封装为函数 【2】 通过模块的Process类创建进程对象,关联函数 【3】 可以通过进程对象设置进程信息及属性 【4】 通过进程对象调用start启动进程 【5】 通过进程对象调用join回收进程
进程对象属性
p.name 进程名称
p.pid 对应子进程的PID号
p.is_alive() 查看子进程是否在生命周期
p.daemon 设置父子进程的退出关系
- 如果设置为True则子进程会随父进程的退出而结束
- 要求必须在start()前设置
- 如果daemon设置成True 通常就不会使用 join()
代码举例:
"""
进程对象属性
"""
from multiprocessing import Process
import time
def fun():
for i in range(3):
print(time.ctime())
time.sleep(2)
# 创建进程对象
p = Process(target=fun,name = "Tarena")
p.daemon = True # 父进程退出时,它创建的这个子进程也退出
p.start()
# p.name = "Tedu"
print("Name:",p.name)
print("is alive:",p.is_alive())
print("PID:",p.pid)
time.sleep(1)
自定义进程类
- 创建步骤 【1】 继承Process类 【2】 重写
__init__方法添加自己的属性,使用super()加载父类属性 【3】 重写run()方法- 使用方法 【1】 实例化对象 【2】 调用start自动执行run方法 【3】 调用join回收进程
代码举例:
"""
自定义进程类
"""
from multiprocessing import Process
# 自己定义一个进程类
class MyProcess(Process):
def __init__(self,value):
super().__init__() # 加载父类的init中的属性
self.value = value
# 充分发挥才能,实现你的进程事件
def fun1(self):
print("步骤一")
def fun2(self):
print("步骤二")
# 功能启动函数
def run(self):
self.fun1()
self.fun2()
p = MyProcess(2) # 定义进程对象
p.start() # 将run作为进程执行
p.join()
进程池
- 必要性 【1】 进程的创建和销毁过程消耗的资源较多 【2】 当任务量众多,每个任务在很短时间内完成时,需要频繁的创建和销毁进程。此时对计算机压力较大 【3】 进程池技术很好的解决了以上问题。
- 原理
创建一定数量的进程来处理事件,事件处理完进 程不退出而是继续处理其他事件,直到所有事件全都处理完毕统一销毁。增加进程的重复利用,降低资源消耗。
进程池实现
【1】 创建进程池对象,放入适当的进程
from multiprocessing import Pool
Pool(processes)
功能: 创建进程池对象
参数: 指定进程数量,默认根据系统自动判定
【2】 将事件加入进程池队列执行
pool.apply_async(func,args,kwds)
功能: 使用进程池执行 func事件
参数: func 事件函数
args 元组 给func按位置传参
kwds 字典 给func按照键值传参
返回值: 返回函数事件对象
【3】 关闭进程池
pool.close()
功能: 关闭进程池
【4】 回收进程池中进程
pool.join()
功能: 回收进程池中进程
"""
进程池演示
* 父进程结束,进程池也会销毁
* 执行的事件函数必须在进程池创建之前声明
"""
from multiprocessing import Pool
from time import sleep,ctime
# 进程池事件
def worker(msg):
sleep(2)
print(ctime(),'--',msg)
# 创建进程池
pool = Pool(4)
# 向进程池放事件
for i in range(10):
msg = "Tedu%d"%i
pool.apply_async(func=worker,args=(msg,))
# 关闭进程池 不能再添加新的事件
pool.close()
# 回收
pool.join()
线程(Thread)理论基础
定义
- 什么是线程 【1】 线程被称为轻量级的进程 【2】 线程也可以使用计算机多核资源,是多任务编程方式 【3】 线程是系统分配内核的最小单元 【4】 线程可以理解为进程的分支任务
- 线程特征 【1】 一个进程中可以包含多个线程 【2】 线程也是一个运行行为,消耗计算机资源 【3】 一个进程中的所有线程共享这个进程的资源 【4】 多个线程之间的运行互不影响各自运行 【5】 线程的创建和销毁消耗资源远小于进程 【6】 各个线程也有自己的ID等特征
threading模块创建线程
【1】 创建线程对象
from threading import Thread
t = Thread()
功能:创建线程对象
参数:target 绑定线程函数
args 元组 给线程函数位置传参
kwargs 字典 给线程函数键值传参
【2】 启动线程
t.start()
【3】 回收线程
t.join([timeout])
demo1:
"""
thread1.py 创建线程演示
步骤 :同Process用法
1. 封装线程函数
2. 创建线程对象
3. 启动线程
4. 回收线程
"""
from threading import Thread
from time import sleep
import os
a = 1
# 线程函数
def music():
for i in range(3):
sleep(2)
print(os.getpid(),"播放:黄河大合唱")
global a
print('a = ',a)
a = 1000
# 创建线程对象
t = Thread(target=music)
t.start() # 启动线程 将music函数作为线程执行内容
for i in range(4):
sleep(1)
print(os.getpid(),"播放:葫芦娃")
t.join() # 回收线程
print("a:",a)
demo2:
"""
thread2.py 线程函数传参
"""
from threading import Thread
from time import sleep
# 含有参数的线程函数
def fun(sec,name):
print("含有参数的线程")
sleep(sec)
print("%s执行完毕"%name)
# 创建多个线程
jobs = []
for i in range(5):
t = Thread(target=fun,args=(2,),kwargs={'name':"T%d"%i})
jobs.append(t) # 存储线程对象
t.start()
for i in jobs:
i.join()
线程对象属性
t.name 线程名称 t.setName() 设置线程名称 t.getName() 获取线程名称
t.is_alive() 查看线程是否在生命周期
t.daemon 设置主线程和分支线程的退出关系 t.setDaemon() 设置daemon属性值 t.isDaemon() 查看daemon属性值
daemon为True时主线程退出分支线程也退出。要在start前设置,通常不和join一起使用。
"""
线程属性
"""
from threading import Thread
from time import sleep
def fun():
sleep(3)
print("线程属性测试")
t = Thread(target = fun)
# 在start前设置,分支线程随主线程结束而结束
t.setDaemon(True)
t.start()
t.setName("Tedu")
print("Name:",t.getName())
print("is alive:",t.is_alive())
print("daemon:",t.isDaemon())
自定义线程类
- 创建步骤 【1】 继承Thread类 【2】 重写
__init__方法添加自己的属性,使用super()加载父类属性 【3】 重写run()方法- 使用方法 【1】 实例化对象 【2】 调用start自动执行run方法 【3】 调用join回收线程
"""
自定义线程类
"""
from threading import Thread
import time
class MyThread(Thread):
def __init__(self,song,sec):
super().__init__()
self.song = song
self.sec = sec
def run(self):
for i in range(3):
print("Playing %s : %s"%(self.song,time.ctime()))
time.sleep(self.sec)
t = MyThread('凉凉',2)
t.start()
t.join()
同步互斥
线程间通信方法
- 通信方法
线程间使用全局变量进行通信
- 共享资源争夺
- 共享资源:多个进程或者线程都可以操作的资源称为共享资源。对共享资源的操作代码段称为临界区。
- 影响 : 对共享资源的无序操作可能会带来数据的混乱,或者操作错误。此时往往需要同步互斥机制协调操作顺序。
- 同步互斥机制
同步 : 同步是一种协作关系,为完成操作,多进程或者线程间形成一种协调,按照必要的步骤有序执行操作。
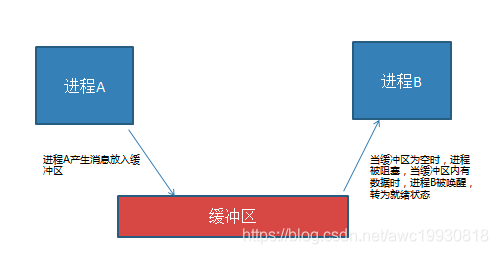
互斥 : 互斥是一种制约关系,当一个进程或者线程占有资源时会进行加锁处理,此时其他进程线程就无法操作该资源,直到解锁后才能操作。
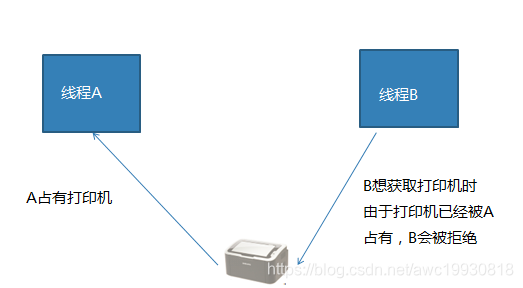
线程同步互斥方法
- 线程Event
from threading import Event
e = Event() 创建线程event对象
e.wait([timeout]) 阻塞等待e被set
e.set() 设置e,使wait结束阻塞
e.clear() 使e回到未被设置状态
e.is_set() 查看当前e是否被设置
"""
event 线程同步互斥方法示例
"""
from threading import Event,Thread
s = None # 在线程之间进行通信
e = Event() # 创建event对象
# 线程函数
def yzr():
print("杨子荣前来拜山头")
global s
s = "天王盖地虎"
e.set() # 解除主线程阻塞
t = Thread(target=yzr)
t.start()
# 主线程验证信息
print("说对口令就是自己人")
e.wait() # 在主线程使用之前先阻塞
if s == '天王盖地虎':
print("宝塔镇河妖")
print("确认过眼神,你是对的人")
else:
print("打死他,无情啊")
t.join()
- 线程锁
from threading import Lock
lock = Lock() 创建锁对象
lock.acquire() 上锁 如果lock已经上锁再调用会阻塞
lock.release() 解锁
with lock: 上锁
...
...
with代码块结束自动解锁
"""
thread_lock.py lock方法解决同步互斥
"""
from threading import Thread,Lock
a = b = 0
lock = Lock() # 创建锁对象
# 线程函数
def value():
while True:
lock.acquire()
if a != b:
print("a = %d,b = %d"%(a,b))
lock.release()
t = Thread(target=value)
t.start()
while True:
lock.acquire() # 上锁
a += 1
b += 1
lock.release() # 解锁
# with lock: #上锁
# a += 1
# b += 1
# 语句块结束解锁
t.join()
死锁及其处理
- 定义
死锁是指两个或两个以上的线程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁。
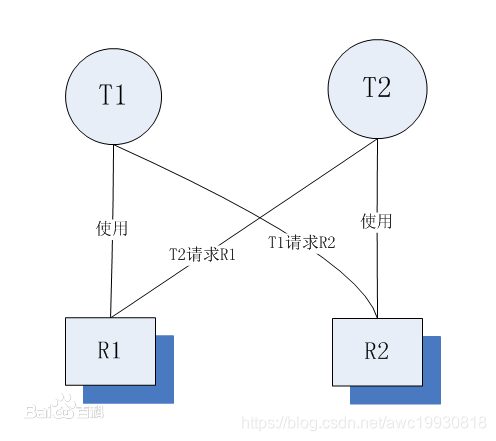
- 死锁产生条件
代码示例: day8/dead_lock.py
死锁发生的必要条件
- 互斥条件:指线程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用毕释放。
- 请求和保持条件:指线程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求线程阻塞,但又对自己已获得的其它资源保持不放。
- 不剥夺条件:指线程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放,通常CPU内存资源是可以被系统强行调配剥夺的。
- 环路等待条件:指在发生死锁时,必然存在一个线程——资源的环形链,即进程集合{T0,T1,T2,···,Tn}中的T0正在等待一个T1占用的资源;T1正在等待T2占用的资源,……,Tn正在等待已被T0占用的资源。
死锁的产生原因
简单来说造成死锁的原因可以概括成三句话:
- 当前线程拥有其他线程需要的资源
- 当前线程等待其他线程已拥有的资源
- 都不放弃自己拥有的资源
- 如何避免死锁
死锁是我们非常不愿意看到的一种现象,我们要尽可能避免死锁的情况发生。通过设置某些限制条件,去破坏产生死锁的四个必要条件中的一个或者几个,来预防发生死锁。预防死锁是一种较易实现的方法。但是由于所施加的限制条件往往太严格,可能会导致系统资源利用率。
"""
模仿死锁现象
"""
from threading import Lock,Thread
from time import sleep
# 账户
class Account:
def __init__(self,id,balance,lock):
self.id = id
self.balance = balance # 存款
self.lock = lock
# 初始化2个账户
Tom = Account('1',5000,Lock())
Abby = Account('2',4000,Lock())
# 转账
def transfer(f,t,amount):
"""
:param f: 转出
:param t: 转入
:param amount: 金额
"""
f.lock.acquire() # 自己的锁住
f.balance -= amount
f.lock.release() # 账户解锁 不会产生死锁
sleep(0.1)
t.lock.acquire() # 对方的账户锁住
t.balance += amount
# f.lock.release() # 账户解锁 会产生死锁
t.lock.release()
t1 = Thread(target=transfer,args=(Tom,Abby,1500))
t2 = Thread(target=transfer,args=(Abby,Tom,500))
t1.start()
t2.start()
t1.join()
t2.join()
print("Tom:",Tom.balance)
print("Abby:",Abby.balance)
Python线程GIL
- python线程的GIL问题 (全局解释器锁)
什么是GIL :由于python解释器设计中加入了解释器锁,导致python解释器同一时刻只能解释执行一个线程,大大降低了线程的执行效率。
导致后果: 因为遇到阻塞时线程会主动让出解释器,去解释其他线程。所以python多线程在执行多阻塞高延迟IO时可以提升程序效率,其他情况并不能对效率有所提升。
GIL问题建议
- 尽量使用进程完成无阻塞的并发行为
- 不使用c作为解释器 (Java C#)
- 结论 : 在无阻塞状态下,多线程程序和单线程程序执行效率几乎差不多,甚至还不如单线程效率。但是多进程运行相同内容却可以有明显的效率提升。
进程线程的区别联系
区别联系
- 两者都是多任务编程方式,都能使用计算机多核资源
- 进程的创建删除消耗的计算机资源比线程多
- 进程空间独立,数据互不干扰,有专门通信方法;线程使用全局变量通信
- 一个进程可以有多个分支线程,两者有包含关系
- 多个线程共享进程资源,在共享资源操作时往往需要同步互斥处理
- 进程线程在系统中都有自己的特有属性标志,如ID,代码段,命令集等。
使用场景
- 任务场景:如果是相对独立的任务模块,可能使用多进程,如果是多个分支共同形成一个整体任务可能用多线程
- 项目结构:多种编程语言实现不同任务模块,可能是多进程,或者前后端分离应该各自为一个进程。
- 难易程度:通信难度,数据处理的复杂度来判断用进程间通信还是同步互斥方法。
要求
- 对进程线程怎么理解/说说进程线程的差异
- 进程间通信知道哪些,有什么特点
- 什么是同步互斥,你什么情况下使用,怎么用
- 给一个情形,说说用进程还是线程,为什么
- 问一些概念,僵尸进程的处理,GIL问题,进程状态
多进程多线程爬虫思路总结
多线程爬虫思路梳理
1.创建线程队列,将待爬取的URL放入队列中
2.多个线程从队列中读取URL地址,进行数据抓取
注意:读取URL地址的过程中注意阻塞问题。
原因:一般实现思路是:
1.创建空队列
2.功能方法生成目标URL – 入队列
3.线程读取URL队列 – 如果为空 – 阻塞等待
– 如果不为空 – 非阻塞 – 读取 – 执行
如果URL队列为空(即还没有生成的URL入队列),线程从中取不到URL,所以会保持阻塞状态,直至功能函数创建完最终URL并入队列,队列此时不为空,线程从中可以读取到URL地址,则转为非阻塞状态,读取,执行。
而入队列我们采用的是put()方法,线程从队列中读取URL采用get()方法,get读取到一个URL后转入非阻塞状态执行线程,同时会从队列中删除读取到的URL,如果此时队列只有这一个URL,则另一线程需继续保持阻塞状态等待下一条URL入队列。
3.因为多线程间通信采用共享全局变量,所以为避免互斥,需要将线程加锁。一般在爬虫程序中需要在写入数据的时候进行加锁,避免因互斥造成数据出错。
多线程爬虫编码步骤
1.init()方法中创建队列,需要几个创建几个
2.init()方法中定义线程锁
3.爬虫类的写入数据方法中,在写入数据步骤前,加锁,写入完毕后,解锁
4.定义所需的线程事件函数
5.主函数中创建多线程,传入线程事件函数,执行。
案例:采用多线程技术爬取小米应用商店数据
参见代码:Spider_Codes/demo16_XiaoMiappsSpider_OOP.py
案例:多线程爬虫爬取腾讯招聘职位信息并写入excel文件
参见代码:Spider_Codes/demo17_TencentJobSpiderThread_OOP.py
cookie模拟登录
会话(Session)跟踪是Web程序中常用的技术,用来跟踪用户的整个会话。常用的会话跟踪技术是Cookie与Session。Cookie通过在客户端记录信息确定用户身份,Session通过在服务器端记录信息确定用户身份。
cookie及session介绍
cookie机制
在程序中,会话跟踪是很重要的事情。理论上,一个用户的所有请求操作都应该属于同一个会话,而另一个用户的所有请求操作则应该属于另一个会话,二者不能混淆。例如,用户A在超市购买的任何商品都应该放在A的购物车内,不论是用户A什么时间购买的,这都是属于同一个会话的,不能放入用户B或用户C的购物车内,这不属于同一个会话。
而Web应用程序是使用HTTP协议传输数据的。HTTP协议是无状态的协议。一旦数据交换完毕,客户端与服务器端的连接就会关闭,再次交换数据需要建立新的连接。这就意味着服务器无法从连接上跟踪会话。即用户A购买了一件商品放入购物车内,当再次购买商品时服务器已经无法判断该购买行为是属于用户A的会话还是用户B的会话了。要跟踪该会话,必须引入一种机制。
Cookie就是这样的一种机制。它可以弥补HTTP协议无状态的不足。在Session出现之前,基本上所有的网站都采用Cookie来跟踪会话。
Cookie意为“甜饼”,是由W3C组织提出,最早由Netscape社区发展的一种机制。目前Cookie已经成为标准,所有的主流浏览器如IE、Netscape、Firefox、Opera等都支持Cookie。
由于HTTP是一种无状态的协议,服务器单从网络连接上无从知道客户身份。怎么办呢?就给客户端们颁发一个通行证吧,每人一个,无论谁访问都必须携带自己通行证。这样服务器就能从通行证上确认客户身份了。这就是Cookie的工作原理。
Cookie实际上是一小段的文本信息。客户端请求服务器,如果服务器需要记录该用户状态,就使用response向客 户端浏览器颁发一个Cookie。客户端浏览器会把Cookie保存起来。当浏览器再请求该网站时,浏览器把请求的网址连同该Cookie一同提交给服务 器。服务器检查该Cookie,以此来辨认用户状态。服务器还可以根据需要修改Cookie的内容。
session机制
除了使用Cookie,Web应用程序中还经常使用Session来记录客户端状态。Session是服务器端使用的一种记录客户端状态的机制,使用上比Cookie简单一些,相应的也增加了服务器的存储压力。
Session是另一种记录客户状态的机制,不同的是Cookie保存在客户端浏览器中,而Session保存在服务器上。客户端浏览器访问服务器的时候,服务器把客户端信息以某种形式记录在服务器上。这就是Session。客户端浏览器再次访问时只需要从该Session中查找该客户的状态就可以了。
如果说Cookie机制是通过检查客户身上的“通行证”来确定客户身份的话,那么Session机制就是通过检查服务器上的“客户明细表”来确认客户身份。Session相当于程序在服务器上建立的一份客户档案,客户来访的时候只需要查询客户档案表就可以了。
cookie模拟登录适用场景
需要登录验证才能访问的页面
cookie模拟登录实现的三种方法
# 方法1(利用cookie)
1、先登录成功1次,获取到携带登陆信息的Cookie(处理headers)
2、利用处理的headers向URL地址发请求
# 方法2(利用requests.get()中cookies参数)
1、先登录成功1次,获取到cookie,处理为字典
2、res=requests.get(xxx,cookies=cookies)
# 方法3(利用session会话保持)
1、实例化session对象
session = requests.session()
2、先post : session.post(post_url,data=post_data,headers=headers)
1、登陆,找到POST地址: form -> action对应地址
2、定义字典,创建session实例发送请求
# 字典key :<input>标签中name的值(email,password)
# post_data = {'email':'','password':''}
3、再get : session.get(url,headers=headers)
案例:人人网携带cookie登录(手动抓取 and 抓取cookie处理为字典 and 使用requests处理cookie)
参见代码:Spider_Code/demo18_RenRenLoginSpider_OOP.py
参见代码:Spider_Code/demo18_RenRenLoginSpider_dicts_OOP.py
参见代码:Spider_Code/demo18_RenRenLogin_requests_cookie_OOP.py</font></p>




