
Python爬虫案例20:主流短视频平台视频下载
作者:Barranzi_
个人github主页:[github](https://github.com/La0bALanG)
个人邮箱:awc19930818@outlook.com
新时代的铁饭碗:一辈子不管走到哪里都有饭吃(还能吃上热乎的)。——佚名
免责声明:
本系列笔记撰写初衷就是为了分享个人知识以及个人学习历程中的感悟及思考,所涉及到的内容`仅供学习与交流`,请勿用作`非法或商业用途`!由此引发的任何法律纠纷`后果自负`,与作者本人无关!
版权声明:
未经作者本人授权,禁止转载!请尊重原创!

注:本文所有代码、案例测试环境:1.Linux -- 系统版本:Ubuntu20.04 LTS 2.windows -- 系统版本:WIN10 64位家庭版
主流短视频平台字节系之——皮皮虾视频下载
通过手机端浏览视频时点击“复制链接”得到的链接进行视频下载:
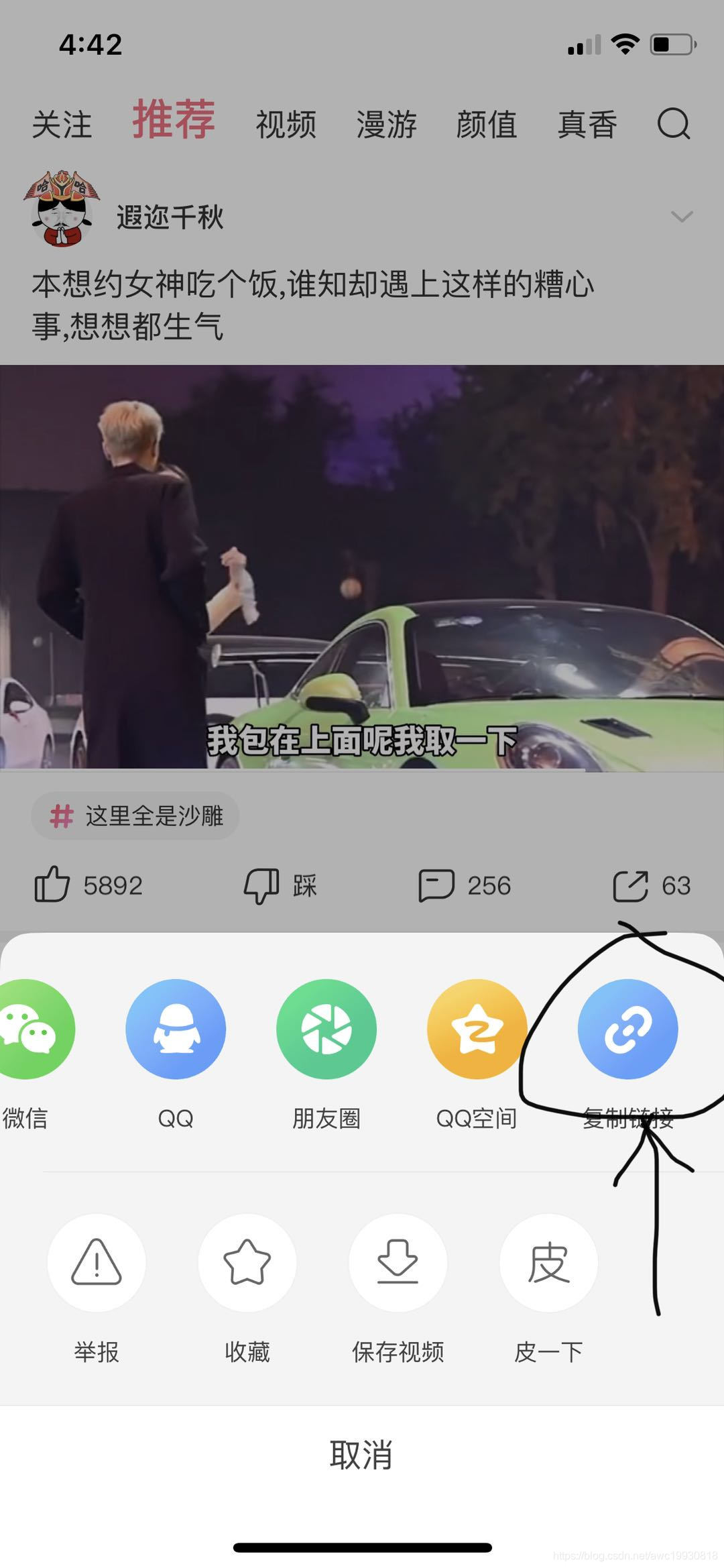
假设现在我们得到这样一个短视频:
https://h5.pipix.com/s/Jf2FVpA/
浏览器打开 – F12 – XHR,找到如下位置:
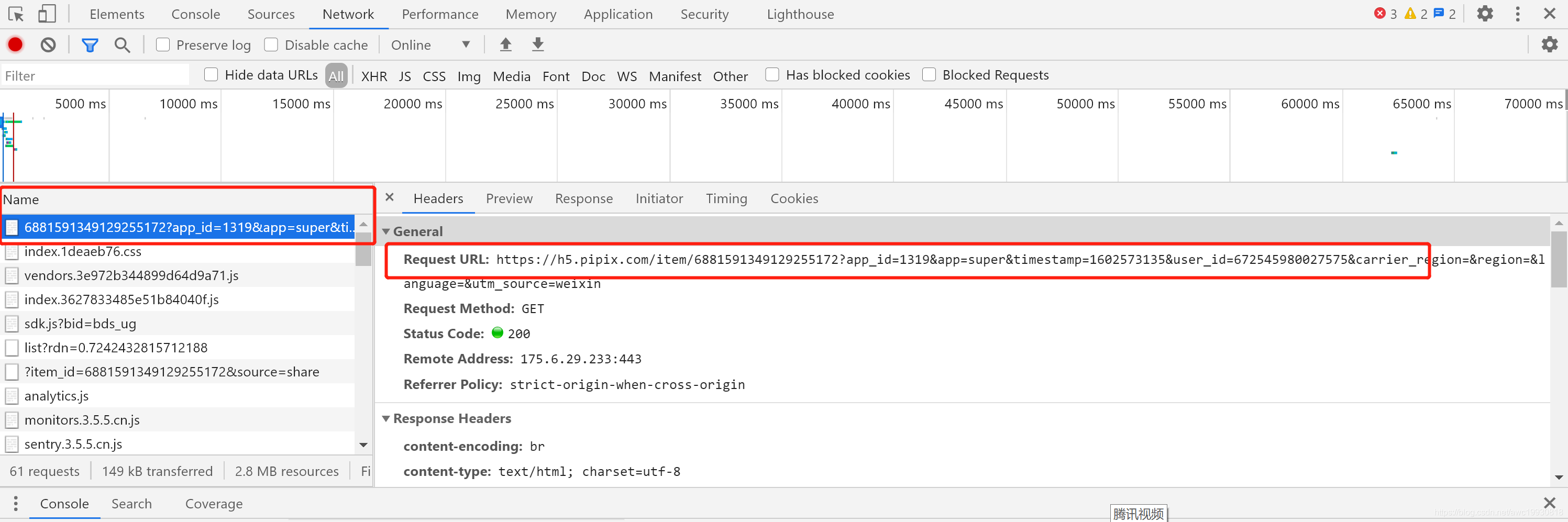
我们发现,请求的URL改变了,看上去上面复制出来的链接是个伪链接,好像有点难度…
先不管,我们继续看。
切换到XHR查看异步包,在这里我们发现了目标视频的下载地址:
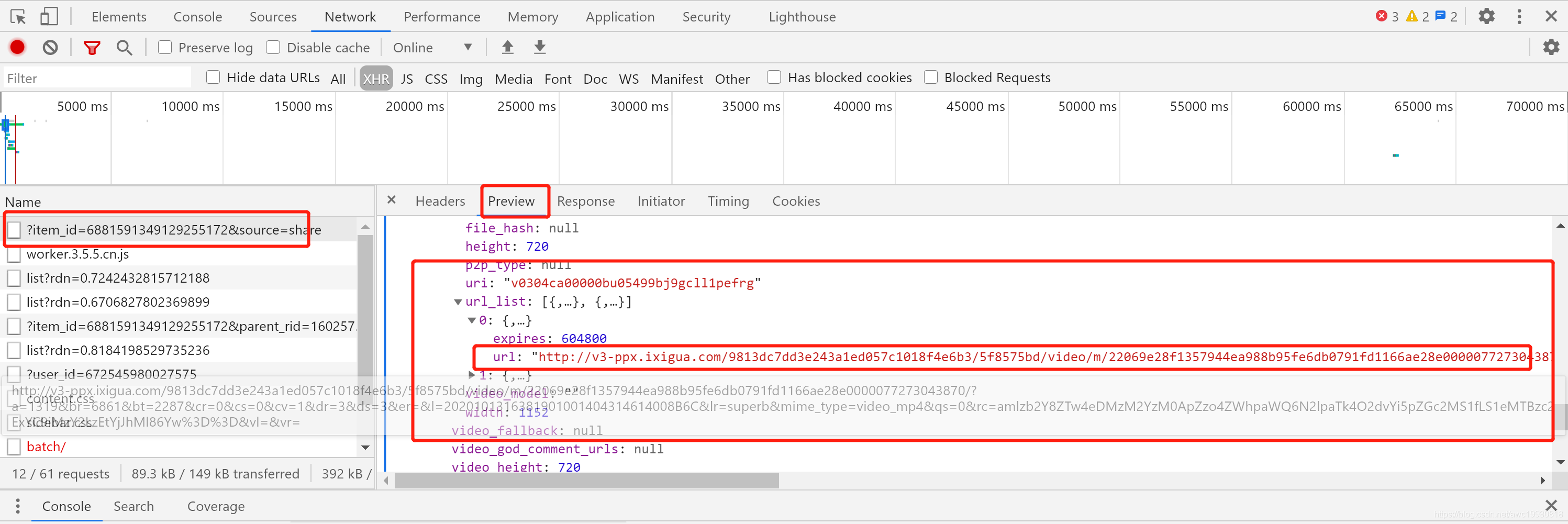
欧克,还好,最起码是能在XHR请求项里找到URL的,但是该接口的请求URL我们看一下:
https://h5.pipix.com/bds/webapi/item/detail/?item_id=6881591349129255172&source=share
看上去也就item_id这个参数是变化的,其余不变,那么这个参数在哪能找到呢?没错细心的靓仔已经找到了,就在页面的真实请求URL里:
https://h5.pipix.com/item/6881591349129255172?app_id=1319&app=super×tamp=1602573135&user_id=672545980027575&carrier_region=®ion=&language=&utm_source=weixin
那问题简单了,只要从中解析出这个item_id不就完事了么?
我们先验证一下,刚才在XHR中看到的视频下载链接是否真实可下:
http://v3-ppx.ixigua.com/9813dc7dd3e243a1ed057c1018f4e6b3/5f8575bd/video/m/22069e28f1357944ea988b95fe6db0791fd1166ae28e0000077273043870/?a=1319&br=6861&bt=2287&cr=0&cs=0&cv=1&dr=3&ds=3&er=&l=2020101316381901001404314614008B6C&lr=superb&mime_type=video_mp4&qs=0&rc=amlzb2Y8ZTw4eDMzM2YzM0ApZzo4ZWhpaWQ6N2lpaTk4O2dvYi5pZGc2MS1fLS1eMTBzc2ExYC9iMzY2LzEtYjJhMl86Yw%3D%3D&vl=&vr=
如图:
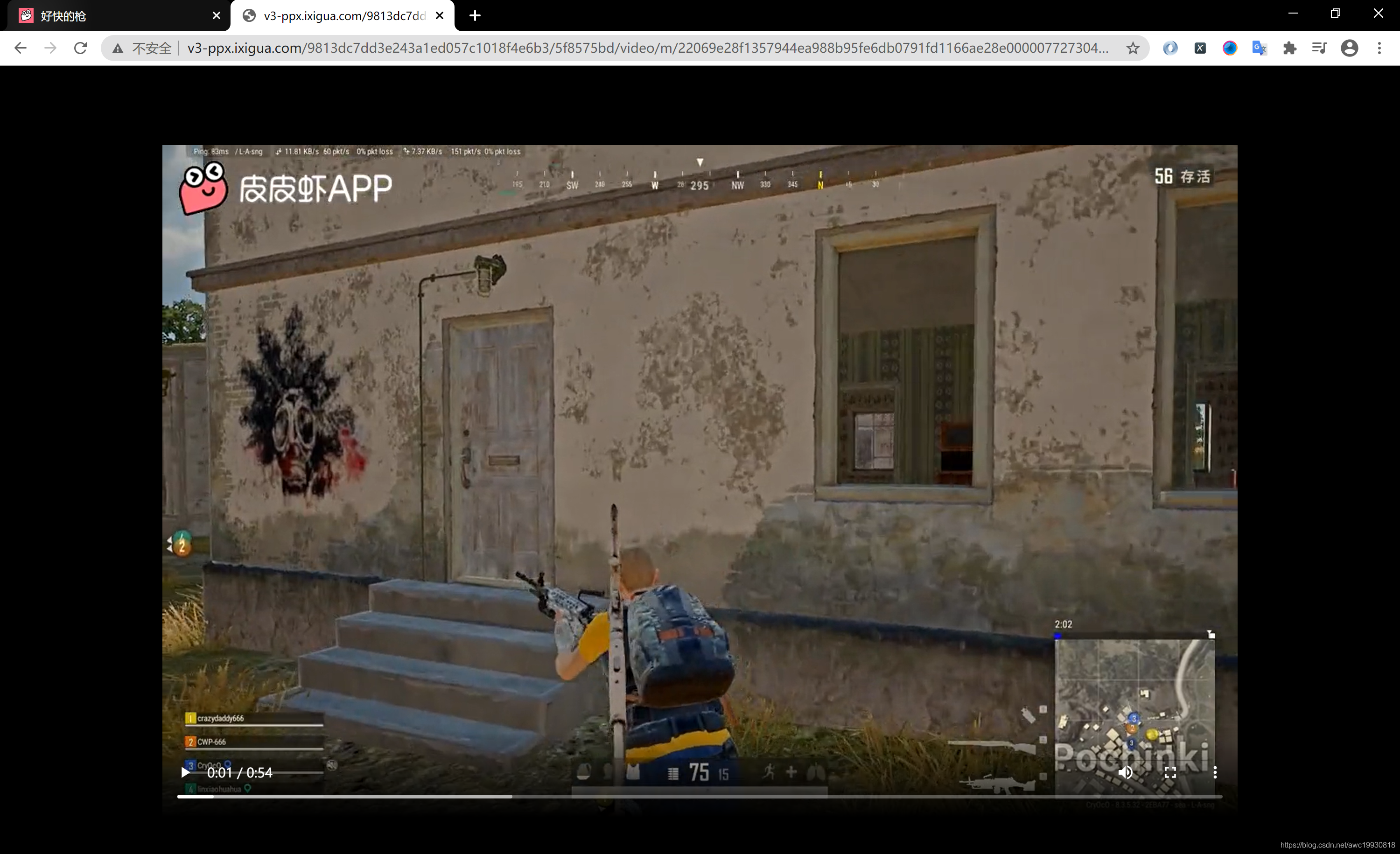
ok,确定该视频可下载,接下来我们总结一下思路:
1.请求从手机中复制出来的链接,访问该视频页;
2.F12控制台抓包拿到该次请求的真实URL链接;
3.从中使用re正则表达式提取出item_id号;
4.为XHR接口的请求URL拼接该item_id号;
5.请求该XHR接口获得响应json;
6.从中提取视频名称及下载链接;
7.请求最终视频的下载URL,保存至本地即可。
上代码:
def ppxDownloads(self,url):
#1.获取item_id
try:
item_id = str(self.get_html(url).url).split('/')[-1].split('?')[0]
except Exception:
print('item_id获取出错')
sys.exit()
#2.拼接视频接口URL链接:
v_xhr_url = 'https://h5.pipix.com/bds/webapi/item/detail/?item_id={}&source=share'.format(item_id)
#3.请求该接口获取响应内容,提取视频名称及下载链接:
try:
req_xhr = self.get_html(v_xhr_url)
except Exception:
print('接口数据获取失败!响应状态吗:',req_xhr.status_code)
sys.exit()
xhr_data = req_xhr.json()
video_url = xhr_data['data']['item']['video']['video_download']['url_list'][0]['url']
video_name = xhr_data['data']['item']['content']
#4.请求视频内容,保存为二进制格式,等待文件写入
finall_video = self.get_html(video_url).content
#5.文件写入
filename = video_name + '.mp4'
with open(filename,'wb') as f:
f.write(finall_video)
return video_name
测试结果:
H:\老安课程串讲资料\文档、代码杂七八\venv\Scripts\python.exe H:/老安课程串讲资料/文档、代码杂七八/BarranziLessonSource/PythonSpider/Spider_Code/demo20_shortVideoDownloadsSpider.py
请选择一个视频平台>>>:皮皮虾
请输入分享链接(程序会自动识别链接):https://h5.pipix.com/s/Jf2FVpA/
识别中...
识别成功,正在获取下载链接...
下载链接获取成功...
开始下载:忍无可忍!印度陆军怒斥军工厂:弹药质量太差,事故频发伤亡惨重.mp4,视频文件较大,请耐心等待...
下载成功!请至本地目录查看!
Process finished with exit code 0
主流短视频平台字节系之——抖音视频下载
毕竟与皮皮虾同出字节系短视频平台,所以其实大致思路是一致的。
首先获取抖音的分享链接:
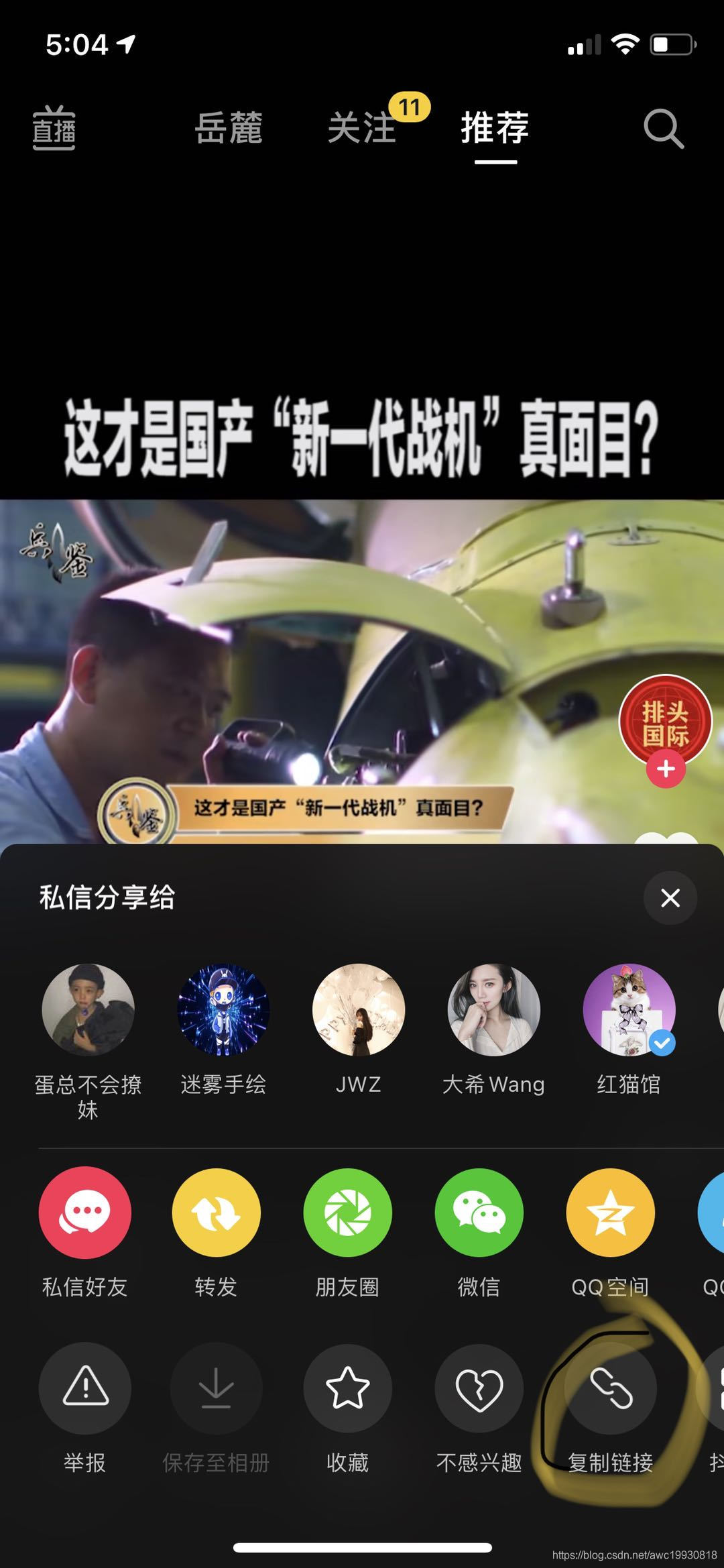
新式“火腿圈蛋”,好看又好吃#自制美食 @抖音小助手 https://v.douyin.com/Jf2NMTv/ 复制此链接,打开抖音,直接观看视频!
如上,因为抖音分享出来的链接配有文字,所以为了拿到这个链接我们需要先用re正则表达式匹配得到:
re.findall('(https?://[^\s]+)', share_str)[0]
得到链接后打开,F12抓包,如下:
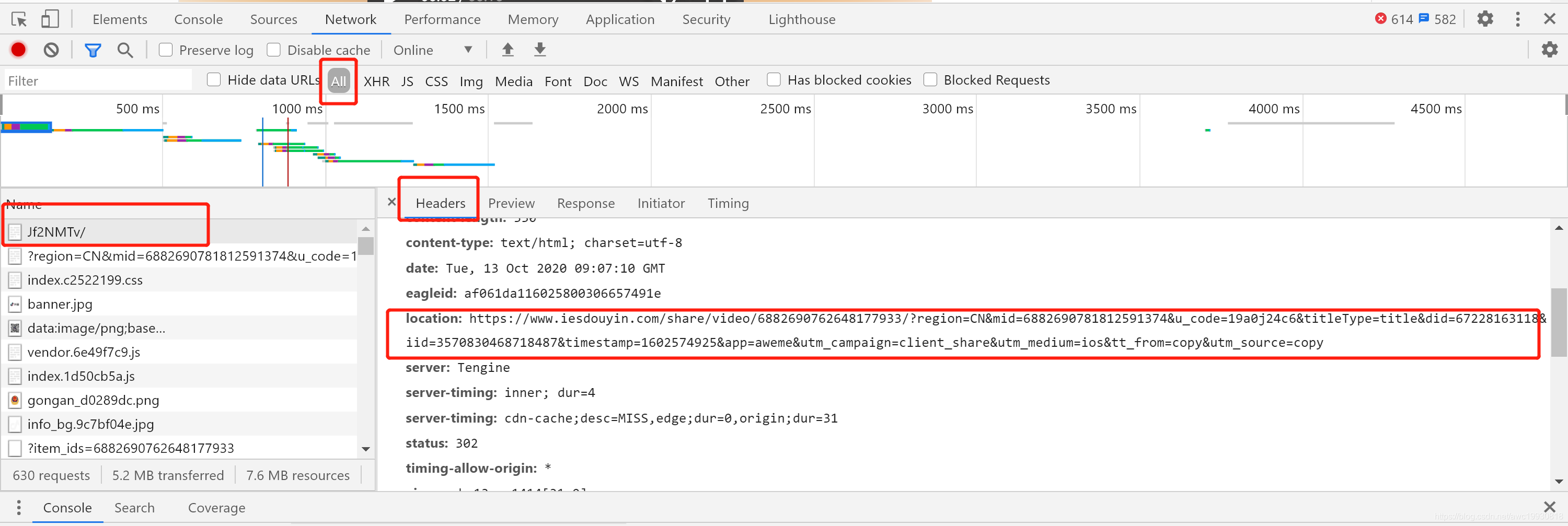
一样,我们先拿到真实请求的URL:
https://www.iesdouyin.com/share/video/6882690762648177933/?region=CN&mid=6882690781812591374&u_code=19a0j24c6&titleType=title&did=67228163118&iid=3570830468718487×tamp=1602574925&app=aweme&utm_campaign=client_share&utm_medium=ios&tt_from=copy&utm_source=copy
继续查看XHR,如下:
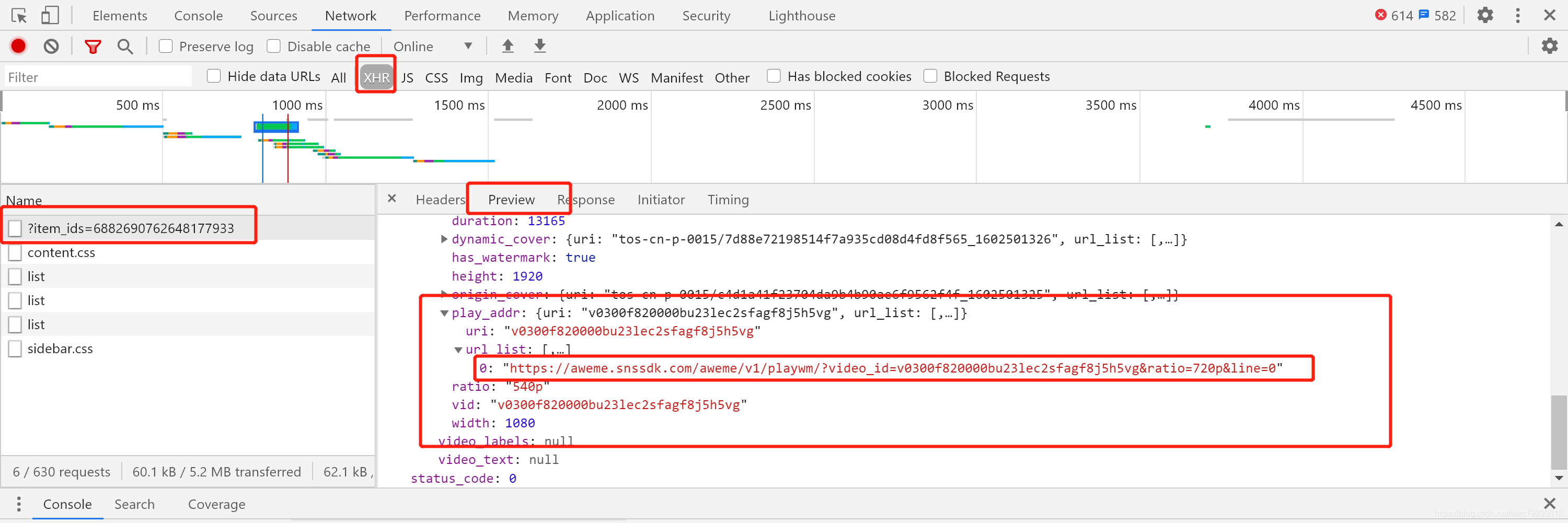
确定该XHR接口响应的json数据中存在视频的下载链接(麻烦,我就不验证能否下载了,肯定能,不信你自己试试)。
现在拿到该XHR接口的请求URL:
https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids=6882690762648177933
观察一下,就一个参数,还是item_ids,找找它需要的参数在哪?没错就在真实请求的URL地址内。
至此,分析完毕,总结一下思路:
1.使用re正则提取分享内容中的链接;
2.请求该链接,获取真实请求URL;
3.从真实请求URL中解析出item_ids号;
4.根据解析得到的item_ids号拼接XHR接口的请求URL;
5.请求该接口,获得响应的json数据,解析视频名称及其下载链接;
6.请求视频下载链接,保存视频至本地。
ok,上代码:
def douyinDownloads(self,url):
# 1.获取item_id
try:
item_id = str(self.get_html(url).url).split('/')[5]
except Exception:
print('item_id获取出错')
sys.exit()
#2.拼接视频接口URL链接:
v_xhr_url = 'https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids={}'.format(item_id)
#3.请求该接口获取响应内容,提取视频名称及下载链接:
try:
req_xhr = self.get_html(v_xhr_url)
except Exception:
print('接口数据获取失败!响应状态吗:',req_xhr.status_code)
sys.exit()
xhr_data = req_xhr.json()
video_url = xhr_data['item_list'][0]['video']['play_addr']['url_list'][0]
video_name = xhr_data['item_list'][0]['desc']
#4.请求视频内容,保存为二进制格式,等待文件写入
finall_video = self.get_html(video_url).content
#5.文件写入
filename = video_name + '.mp4'
with open(filename,'wb') as f:
f.write(finall_video)
return video_name
def test():
'''
测试用例
'''
# print('正在准备代理...')
project = ShortVideoDownloadsSpider()
# print('代理准备完毕,本次代理IP为:%s'%project.proxy['http'])
#
apps_name = input('请选择一个视频平台>>>:')
if apps_name == '皮皮虾':
share_url = input('请输入分享链接(程序会自动识别链接):')
print('识别中...')
time.sleep(1)
print('识别成功,正在获取下载链接...')
time.sleep(1)
print('下载链接获取成功...')
v_name = project.ppxDownloads(share_url)
print('开始下载:%s.mp4,视频文件较大,请耐心等待...'%v_name)
print('下载成功!请至本地目录查看!')
elif apps_name == '抖音':
share_str = input('请输入分享链接(程序会自动识别链接):')
share_url = re.findall('(https?://[^\s]+)', share_str)[0]
print('识别中...')
time.sleep(1)
print('识别成功,正在获取下载链接...')
time.sleep(1)
print('下载链接获取成功...')
v_name = project.douyinDownloads(share_url)
print('开始下载:%s.mp4,视频文件较大,请耐心等待...'%v_name)
print('下载成功!请至本地目录查看!')
if __name__ == '__main__':
test()
测试结果:
H:\老安课程串讲资料\文档、代码杂七八\venv\Scripts\python.exe H:/老安课程串讲资料/文档、代码杂七八/BarranziLessonSource/PythonSpider/Spider_Code/demo20_shortVideoDownloadsSpider.py
请选择一个视频平台>>>:抖音
请输入分享链接(程序会自动识别链接):脑筋急转弯!基本都会!就七个挨揍了!哈哈哈#搞笑 #办公室 https://v.douyin.com/Jf2H7Sh/ 复制此链接,打开抖音,直接观看视频!
识别中...
识别成功,正在获取下载链接...
下载链接获取成功...
开始下载:脑筋急转弯!基本都会!就七个挨揍了!哈哈哈#搞笑 #办公室.mp4,视频文件较大,请耐心等待...
下载成功!请至本地目录查看!
Process finished with exit code 0
未完待续….
下期更新:腾讯微视、快手、最右。
==========================================================================
2020.10.21更新
主流短视频平台——腾讯微视视频下载
微视虽然与字节系完全同属两个不同的生态,但其实抓取视频的话,原理都是大差不差的。只是会在一些小的细节上存在一些差异。
老生常谈,先来个视频的链接吧:
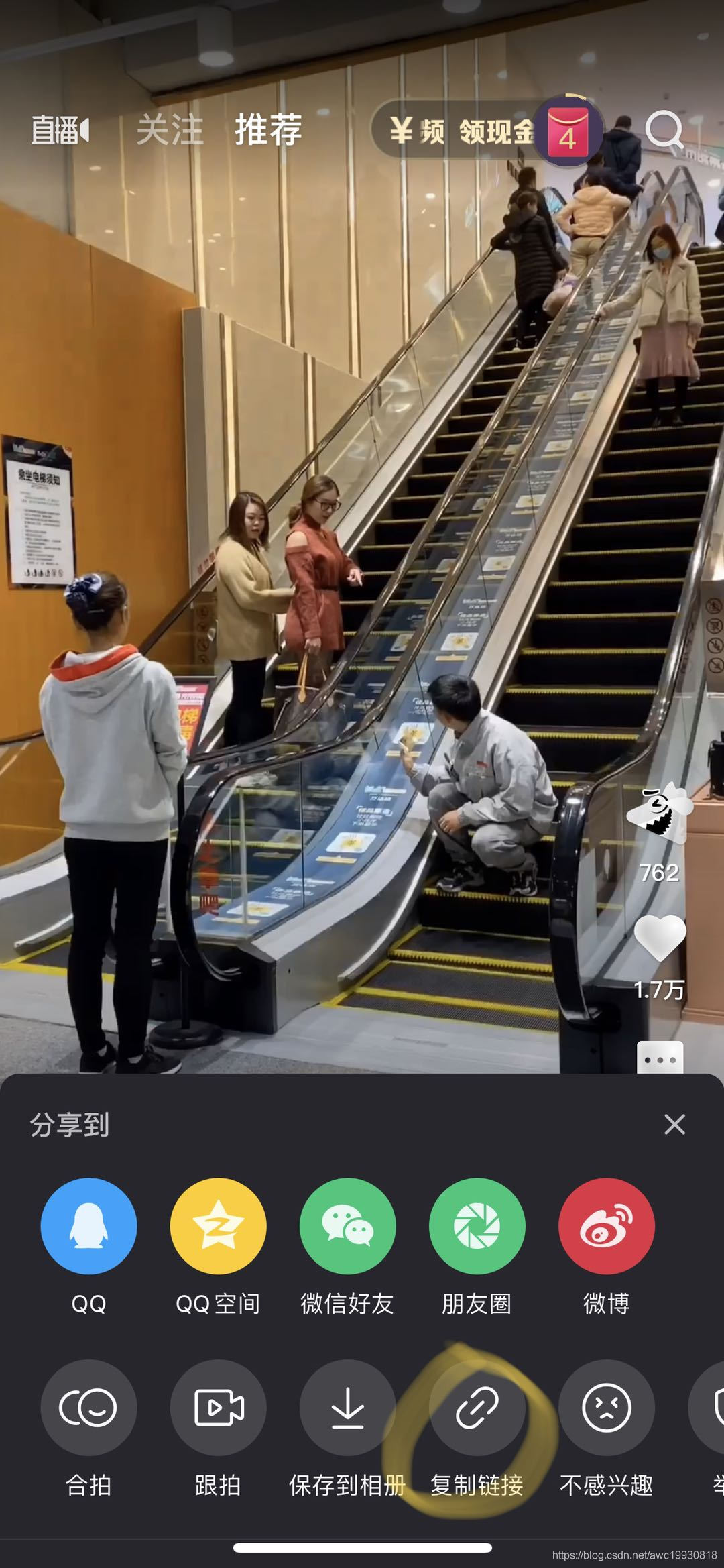
链接:三遍能看懂的是高手,倒过来看看»https://h5.weishi.qq.com/weishi/feed/78sbMEfQl1Kq5VjoV/wsfeed?wxplay=1&id=78sbMEfQl1Kq5VjoV&spid=1581426788924755&qua=v1_iph_weishi_8.3.1_397_app_a&chid=100081014&pkg=3670&attach=cp_reserves3_1000370011
ok。拿到链接后,明显,需要通过re正则表达式提取出链接:
share_url = re.findall('(https?://[^\s]+)', share_str)[0]
提取到链接后,浏览器打开,F12控制台抓包,刷新几次当前页面,观察其XHR加载项,发现如下接口看着比较像视频的加载接口:
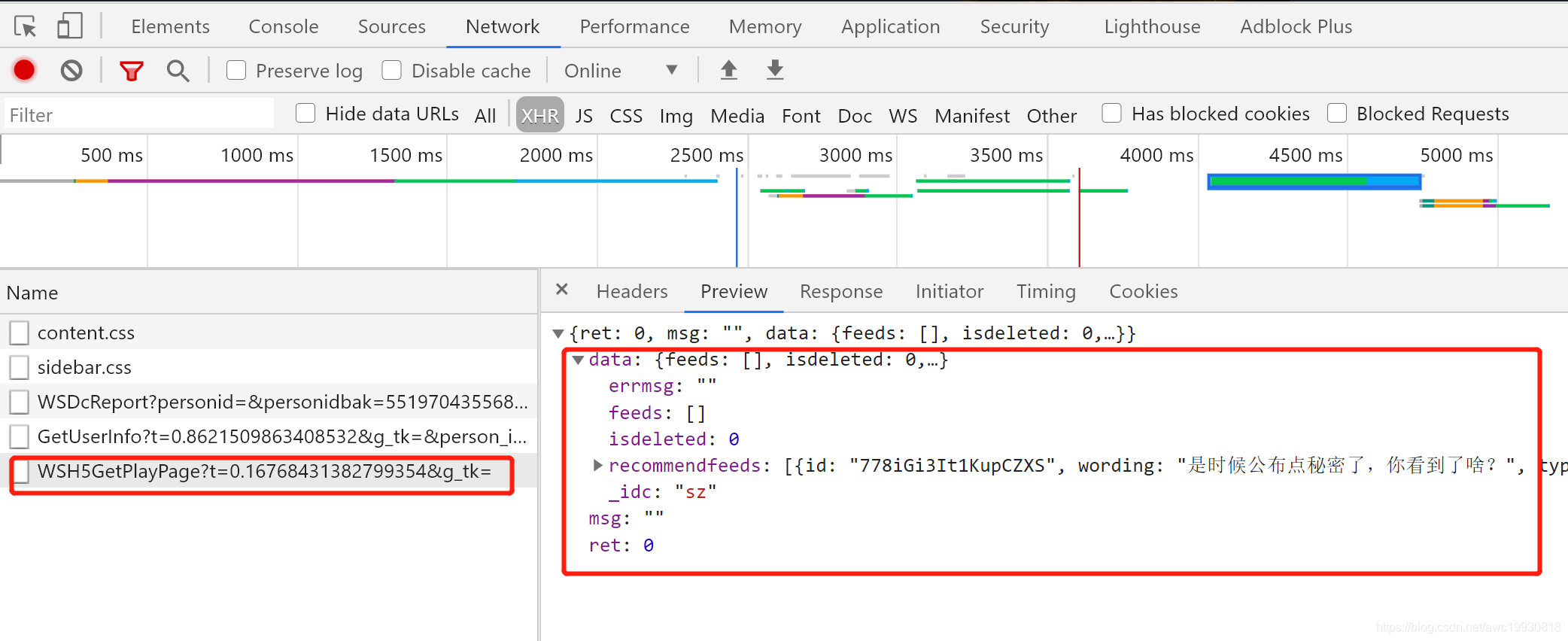
但是在刷新几次你会发现,无论你如何刷新:
1.再没别的接口看着像视频加载了;
2.该接口也无法找到我们想要的数据;
怎么办?
尝试切换到移动端窗口试试。果然,切换至移动端窗口,再刷新当前页面,数据终于出来了:
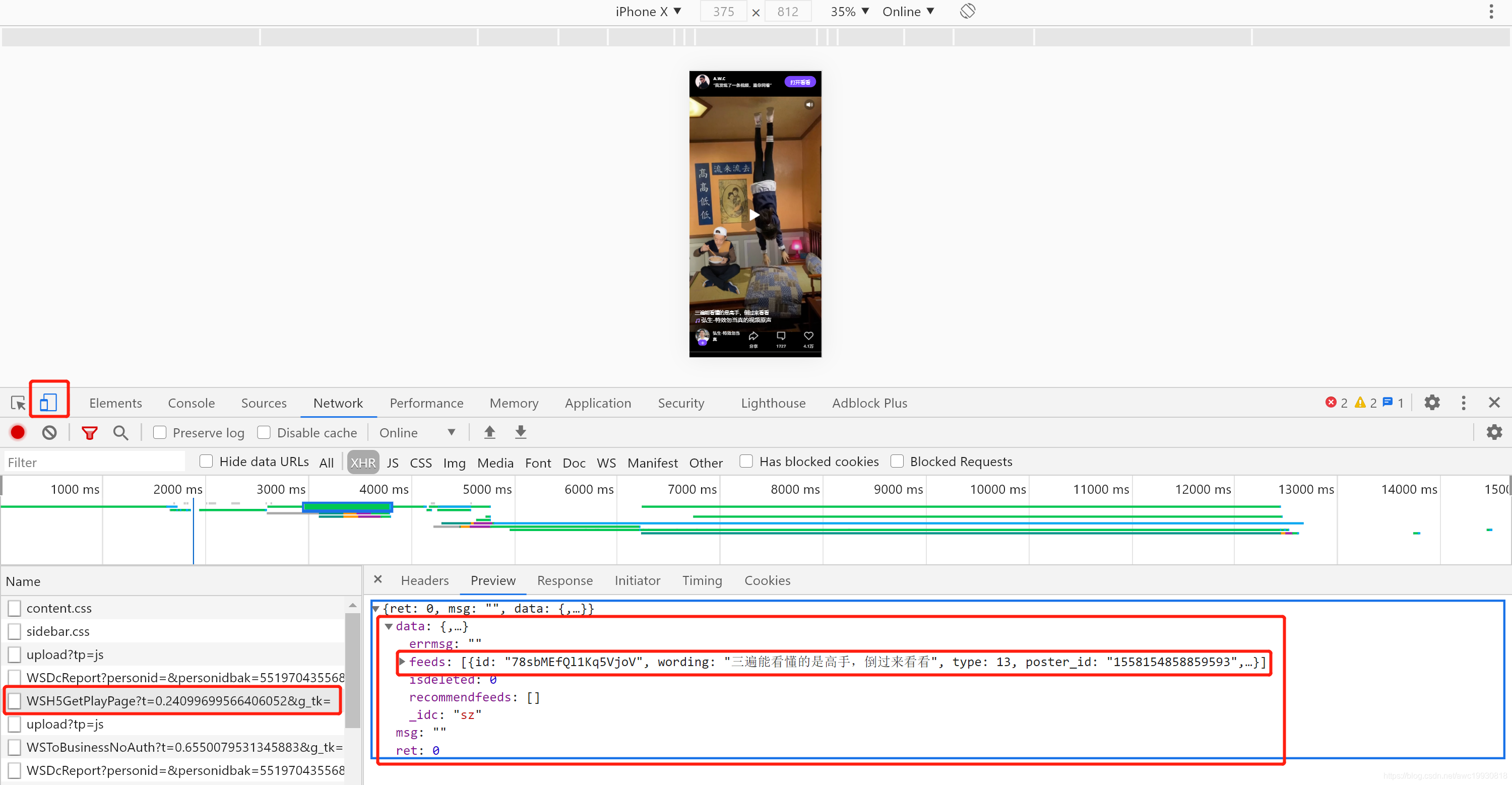
很直观,我们需要的视频下载链接就在其response的json数据中。
想要的内容找到了,接下来分析该接口的URL规律:
https://h5.weishi.qq.com/webapp/json/weishi/WSH5GetPlayPage?t=0.24099699566406052&g_tk=
刷新数次后发现:
t 参数的值一直在变化,变化范围一直在0到1之间,看上去不像时间戳,倒像0到1之间的随机数,我们使用Python自带的random模块模拟一下,再重新拼接至该URL,访问一下:
url = 'https://h5.weishi.qq.com/webapp/json/weishi/WSH5GetPlayPage?t={}&g_tk='.format(random.random())
卧槽成功…
一不小心我们就破解了…
哦了,URL分析完,再继续看;
该请求为POST请求,则往下拉看一下其请求参数:

看上去只有feedid在变化,可是feedid的值在哪找呢?细心的朋友发现了,就在复制出来的原链接:

从中提取出我们所需的feedid参数值:
str(link).split('/')[5]
将其拼接进我们的请求参数中:
forms_data = {
'datalvl': "all",
'feedid': str(link).split('/')[5],
'recommendtype': '0',
'_weishi_mapExt': {}
}
哦了,到此,准备工作完成,开始写代码吧。
奥对了,记得换成移动端的headers,否则请求到的数据feedid为空:
self.iphoneHeaders = {
'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'
}
下面上代码:
def TencentDownloads(self,link):
forms_data = {
'datalvl': "all",
'feedid': str(link).split('/')[5],
'recommendtype': '0',
'_weishi_mapExt': {}
}
url = 'https://h5.weishi.qq.com/webapp/json/weishi/WSH5GetPlayPage?t={}&g_tk='.format(random.random())
try:
req_xhr = self.post_html(url,forms_data)
# req_xhr = requests.post(url=url,data=forms_data,headers=self.iphoneHeaders)
print('请求成功')
except Exception:
print('接口数据获取失败!响应状态吗:',req_xhr.status_code)
sys.exit()
xhr_data = req_xhr.json()
video_name = xhr_data['data']['feeds'][0]['feed_desc'].replace(' ','')
if video_name == '':
video_name = int(random.random() * 2 * 1000)
if len(str(video_name)) > 20:
video_name = video_name[:20]
video_url = xhr_data['data']['feeds'][0]['video_url']
finall_video = self.get_html(video_url).content
filename = video_name + '.mp4'
with open(filename,'wb') as f:
f.write(finall_video)
return video_name
def test():
'''
测试用例
'''
# print('正在准备代理...')
project = ShortVideoDownloadsSpider()
# print('代理准备完毕,本次代理IP为:%s'%project.proxy['http'])
#
apps_name = input('请选择一个视频平台>>>:')
if apps_name == '皮皮虾':
share_url = input('请输入分享链接(程序会自动识别链接):')
print('识别中...')
time.sleep(1)
print('识别成功,正在获取下载链接...')
time.sleep(1)
print('下载链接获取成功...')
v_name = project.ppxDownloads(share_url)
print('开始下载:%s.mp4,视频文件较大,请耐心等待...'%v_name)
print('下载成功!请至本地目录查看!')
elif apps_name == '抖音':
share_str = input('请输入分享链接(程序会自动识别链接):')
share_url = re.findall('(https?://[^\s]+)', share_str)[0]
print('识别中...')
time.sleep(1)
print('识别成功,正在获取下载链接...')
time.sleep(1)
print('下载链接获取成功...')
v_name = project.douyinDownloads(share_url)
print('开始下载:%s.mp4,视频文件较大,请耐心等待...'%v_name)
print('下载成功!请至本地目录查看!')
elif apps_name == '腾讯微视':
share_str = input('请输入分享链接(程序会自动识别链接):')
share_url = re.findall('(https?://[^\s]+)', share_str)[0]
print('识别中...')
time.sleep(1)
print('识别成功,正在获取下载链接...')
time.sleep(1)
print('下载链接获取成功...')
v_name = project.TencentDownloads(share_url)
print('开始下载:%s.mp4,视频文件较大,请耐心等待...'%v_name)
print('下载成功!请至本地目录查看!')
if __name__ == '__main__':
test()
测试结果:
H:/老安课程串讲资料/文档、代码杂七八/BarranziLessonSource/PythonSpider/Spider_Code/demo20_shortVideoDownloadsSpider.py
请选择一个视频平台>>>:腾讯微视
请输入分享链接(程序会自动识别链接):三遍能看懂的是高手,倒过来看看>>https://h5.weishi.qq.com/weishi/feed/78sbMEfQl1Kq5VjoV/wsfeed?wxplay=1&id=78sbMEfQl1Kq5VjoV&spid=1581426788924755&qua=v1_iph_weishi_8.3.1_397_app_a&chid=100081014&pkg=3670&attach=cp_reserves3_1000370011
识别中...
识别成功,正在获取下载链接...
下载链接获取成功...
请求成功
开始下载:三遍能看懂的是高手,倒过来看看.mp4,视频文件较大,请耐心等待...
下载成功!请至本地目录查看!
未完待续…




