
Python爬虫笔记5:Scrapy爬虫框架基础概念及应用
作者:Barranzi_
个人github主页:[github](https://github.com/La0bALanG)
个人邮箱:awc19930818@outlook.com
新时代的铁饭碗:一辈子不管走到哪里都有饭吃(还能吃上热乎的)。——佚名
免责声明:
本系列笔记撰写初衷就是为了分享个人知识以及个人学习历程中的感悟及思考,所涉及到的内容`仅供学习与交流`,请勿用作`非法或商业用途`!由此引发的任何法律纠纷`后果自负`,与作者本人无关!
版权声明:
未经作者本人授权,禁止转载!请尊重原创!

注:本文所有代码、案例测试环境:1.Linux -- 系统版本:Ubuntu20.04 LTS 2.windows -- 系统版本:WIN10 64位家庭版
Scrapy框架基本概念详解及安装&配置
简介
Scrapy是一个开源的,协作的,采用Python编写的爬虫框架,是一个快速、高层次的屏幕抓取和web抓取框架。其最初的目的是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速、简单、可扩展的方式从网站中提取所需的数据。但目前Scrapy的用途十分广泛,可用于如数据挖掘、监测和自动化测试等领域,也可以应用在获取API所返回的数据或者通用的网络爬虫。
Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架。因此Scrapy使用了一种非阻塞(又名异步)的代码来实现并发(基于Twisted实现单线程并发下载页面)。也具备解析下载内容功能、帮助实现“递归”、帮助完成数据持久化(数据写入硬盘或数据库)、还具备一些扩展性功能(自定义组件)。
-
什么是框架?
所谓框架其实就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板。对于框架的学习,重点是要学习其框架的特性、各个功能的用法即可。
Scrapy核心组件(架构)及架构图示
Scrapy核心组件详解
- Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
- Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件):一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的response和从Spider出去的requests)。
Scrapy架构图(援引自:百度百科)
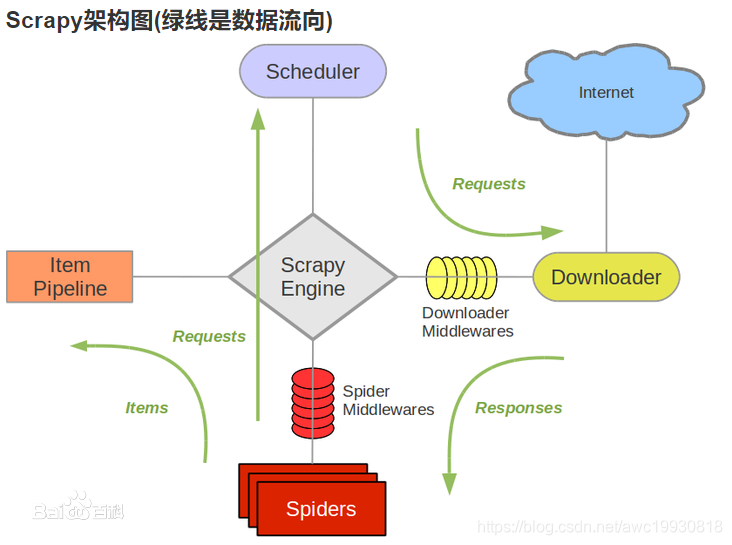
Scrapy工作流程
Scrapy框架大致工作流程如下:
1.引擎:Spider,你需要处理哪个页面或网站?
2.Spider:大哥我需要处理xxx.com。
3.引擎:你把第一个需要处理的URL发给我吧。
4.Spider:好的大哥,第一个处理的URL是xxxx。
5.引擎:调度器,我这现在有个request请求你帮我排序后入一下队列。
6.调度器:好的,正在处理你等一下…[处理完上一个了…]现在开始处理你的请求。
7.引擎:调度器,处理完之后把你处理好的request请求发给我吧。
8.调度器:处理好了,现在把处理好的request发给你。
9.引擎:下载器,你现在按照下载中间件的设置帮我下载一下这个request请求。
10.下载器:好的,开始下载(发起请求)…下载完毕,成功,现在将结果发送给你。(如果失败:对不起,这个request下载失败了。引擎:调度器,刚才那个request下载失败了,你记录一下,我们待会再重新下载)。
11.引擎:Spider,这是下载好的东西,并且已经按照下载器中间件的设置处理过了,你自己在处理一下吧。
12.Spider:(处理完毕数据之后对于需要跟进的URL)引擎大哥,我现在有两个结果,一个是我需要跟进的URL,[或一个是我获取的items数据]
13.引擎:管道,我这有个items数据你帮我处理一下吧。调度器,这个是需要继续跟进的URL,你处理一下。(此时模拟循环,从第4步后开始继续循环,直到获取完所有所需的信息)。
14.管道 and 调度器:好的,开始处理。
- 一般的,采用Scrapy框架编写爬虫程序总体上可分为4步:
- 新建项目:新建一个爬虫新项目
- 明确目标:明确你想要的爬取的目标
- 编写爬虫:完成爬虫程序开始爬取
- 存储内容:设计管道爬取内容
Scrapy框架的安装及配置
Linux环境(以Ubuntu20.04 LTS举例)
-
先安装所需依赖
sudo apt-get install python-dev sudo apt-get install build-essential sudo apt-get install libxml2-dev sudo apt-get install libxslt1-dev sudo apt-get install python-setuptools -
然后再安装scrapy:
pip3 install Scrapy -
验证是否安装成功:终端输入命令:
scrapy
windows环境
直接在本机cmd环境下,或pycharm Terminal里通过pip包管理工具下载安装即可。
命令如下:
pip install Scrapy -i https://pypi.douban.com/simple
安装过程中如果报错,是因为 Twisted 依赖与当前本机python版本不一致,需要去官网:https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载 Twised 对应本机python版本的依赖包:

使用如下命令安装:
pip install D:\virtualenv_space\Twisted-20.3.0-cp39-cp39-win_amd64.whl
手动安装完毕后再执行安装scrapy命令即可成功安装。
Scrapy基本操作及配置介绍
- 基本命令
# 1、创建爬虫项目
scrapy startproject 项目名
# 2、创建爬虫文件
scrapy genspider 爬虫名 域名
# 3、运行爬虫
scrapy crawl 爬虫名
- Scrapy项目目录结构
Baidu # 项目文件夹
├── Baidu # 项目目录
│ ├── items.py # 定义数据结构
│ ├── middlewares.py # 中间件
│ ├── pipelines.py # 数据处理
│ ├── settings.py # 全局配置
│ └── spiders
│ ├── baidu.py # 爬虫文件
└── scrapy.cfg # 项目基本配置文件
- 全局配置文件settings.py详解
# 1、定义User-Agent
USER_AGENT = 'Mozilla/5.0'
# 2、是否遵循robots协议,一般设置为False
ROBOTSTXT_OBEY = False
# 3、最大并发量,默认为16
CONCURRENT_REQUESTS = 32
# 4、下载延迟时间
DOWNLOAD_DELAY = 1
# 5、请求头,此处也可以添加User-Agent
DEFAULT_REQUEST_HEADERS={}
# 6、项目管道
ITEM_PIPELINES={
'项目目录名.pipelines.类名':300
}
- 创建爬虫项目步骤
1、新建项目 :scrapy startproject 项目名
2、cd 项目文件夹
3、新建爬虫文件 :scrapy genspider 文件名 域名
4、明确目标(items.py)
5、写爬虫程序(文件名.py)
6、管道文件(pipelines.py)
7、全局配置(settings.py)
8、运行爬虫 :scrapy crawl 爬虫名
- Pycharm运行Spider项目步骤
1、创建run.py(和scrapy.cfg文件同目录)
2、run.py中内容:
from scrapy import cmdline
cmdline.execute('scrapy crawl maoyan'.split())
示例:Scrapy基本简单使用——百度首页文字简单爬取(熟悉Scrapy基本使用)
-
目标
打开百度首页,把 ‘百度一下,你就知道’ 抓取下来,从终端输出 /html/head/title/text()
-
实现步骤
-
创建项目demo和爬虫文件baidu
scrapy startproject demo cd demo scrapy genspider baidu www.baidu.com -
编写爬虫文件baidu.py,xpath提取“ 百度一下,你就知道”数据
# -*- coding: utf-8 -*- import scrapy class BaiduSpider(scrapy.Spider): name = 'baidu' allowed_domains = ['www.baidu.com'] start_urls = ['http://www.baidu.com/'] def parse(self, response): result = response.xpath('/html/head/title/text()').extract_first() print('*'*50) print(result) print('*'*50) -
全局配置settings.py
USER_AGENT = 'Mozilla/5.0' ROBOTSTXT_OBEY = False DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', } -
创建run.py(和scrapy.cfg同目录)
from scrapy import cmdline cmdline.execute('scrapy crawl baidu'.split()) -
启动爬虫
直接运行run.py即可
python run.py
-




